CPU sizing

Для выполнения сайзинга часто требуется сравнить производительность ядер разных производителей. В данном материале приведена удачная табличка независимого оценщика.




Представлен отрывок из книги Уильяма Инмона "DW 2.0: The Architecture for the Next Generation of Data Warehousing".
"Окружающая среда DW2.0 отказывается от мировоззрения: «запрограммировать, загрузить и взорвать», которое было нормой для хранилищ данных первого поколения. В прошлом качеству данных не уделяли никакого внимания до самого последнего момента...".

Нечёткое (или размытое, расплывчатое, туманное, пушистое) множество - понятие, введённое Лотфи Заде в 1965 г. в статье «Fuzzy Sets» (нечёткие множества) в журнале Information and Control. Л. Заде расширил классическое канторовское понятие множества, допустив, что характеристическая функция (функция принадлежности элемента множеству) может принимать любые значения в интервале [0,1], а не только значения 0 или 1.

В данной статье описывается как подход Кимбалла к архитектуре и построению систем хранилищ данных/бизнес-аналитики (DW/BI) работает с Parallel Data Warehouse от Microsoft, и как этот новый продукт можно включить в Вашу DW/BI систему. В начале статьи кратко описан сам подход и его ключевые принципы. Затем рассматривается архитектура Parallel Data Warehouse (PDW) и обсуждается ее согласованность с подходом Кимбалла.
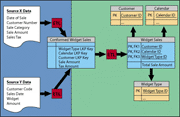
Реализация процесса обнаружения в источнике данных новых, измененных или удаленных записей позволяет ускорить процесс загрузки данных в хранилище за счёт устранения необходимости полного их сравнения. В статье рассмотрены способы реализации захвата изменений (changed data capture).