Качество данных в DW 2.0

Автор: Инмон, Уильям (Inmon, William)
Перевод: Бралгин Игорь
Оригинальный источник: Глава 18 из книги «DW 2.0: The Architecture for the Next Generation of Data Warehousing»
Окружающая среда DW2.0 отказывается от мировоззрения: «запрограммировать, загрузить и взорвать», которое было нормой для хранилищ данных первого поколения. В прошлом качеству данных не уделяли никакого внимания до самого последнего момента – «без 5-ти минут до окончания проекта». Это был момент, когда проектная команда загружала хранилище данными, извлеченными из исходных систем, и только тогда обнаруживала «гремлинов», которые скрывались в исходных данных. Это приводило к огромному разочарованию и значительным срывам сроков осуществления. Проблемы качества данных, обнаруженные во время тестирования или стадии загрузки, могут быть главными причинами опережающих показателей провала проекта: превышения длительности и превышения бюджета.
DW 2.0 – подход следующего поколения к построению хранилищ данных – гарантирует, что команда, ответственная за качество данных, «выезжает» вперед, прежде чем «обоз» хранилища данных вступит в новые территории. Так же, как в былые времена, у пионеров в их фургонных обозах были разведчики, которые шли вперед, разведывая территорию, через которую обоз собирался пройти, так и команды, ответственные за качество данных – это разведчики для команды разработчиков хранилищ данных. Они должны сделать профилирование исходных данных в Интерактивном Секторе (Interactive Sector), чтобы обнаружить проблемы и аномалии данных и заранее оповестить команду разработчиков. Команда профилирования данных должна состоять из профессионалов и в области бизнеса, и в области информационных технологии.
Задачи открытия данных (data discovery) должны быть встроены в методологию и выполняться даже перед началом итерации планирования. (Профилирование данных является лишь одним из мероприятий, необходимых для анализа качества данных; другая задача – проверка, как данные придерживаются правил). Используя этот подход, проектная команда заранее обнаружит многие «подводные камни» данных и поэтому сможет подготовиться к ним.
Обнаруженные проблемы качества данных должны быть эскалированы деловому сообществу, которое должно решить, какие из этих проблем качества данных их беспокоят и должны быть исправлены. Важно понимать, что не все проблемы качества данных важны для бизнеса. Когда бизнес указал, какие из проблем качества данных важны, необходимо идентифицировать бизнес-правила, которые должны быть применены для очистки данных. Эти правила очистки будут основой спецификаций преобразования исходных данных, устраняя сценарий «запрограммировать, загрузить и взорвать».
В хранилищах данных следующего поколения DW 2.0 команда, ответственная за качество данных, будет иметь возможность выбирать стратегию для решения найденных проблем качества данных. Некоторые из этих стратегий следующие:
- Исправить исходные данные: Фактический доступ к базе данных и физическое восстановление данных.
- Исправить исходную программу: Выполнить корректирующие исправления, чтобы сделать данные действительными.
- Исправить бизнес-процессы: «кривые» бизнес процессы очень часто являются основной причиной низкого качества данных.
- Приспособьтесь к изменениям: Осознайте и примите решения в ситуации, когда атрибуты данных используются в целях иных, чем их первоначальное назначение, например, код половой принадлежности, принимающий более двух различных значений.
- Преобразовать данные: Преобразуйте данные по пути в хранилище данных – наиболее распространенная стратегия, но не должна быть единственной используемой стратегией.
В идеальном мире каждый хочет устранить причину проблемы, а не следствие. Исправление программы и данных в источнике и исправление бизнес-процесса являются исправлением причины.
Важно отметить, что есть два альтернативных подхода к преобразованию данных по пути в Интегрированный Сектор (Integrated Sector). Первый подход – просто изменить данные и загрузить их в хранилище данных. Второй подход делает то же самое и дополнительно загружает неизменные данные рядом с трансформированными данными. Есть много случаев, когда это может быть предпочтительной стратегией: бизнес пользователи могут видеть, что было сделано с данными, и поэтому склоны более доверять им.
Инструментальные средства качества данных DW 2.0
Конечно, существует множество видов инструмента, которые можно обсудить. Инструменты профилирования данных находят проблемы в данных. Существует целый набор других инструментов, которые исправляют аномалии данных. Есть инструменты, которые контролируют качество данных, другие создают отчеты о качестве данных. Инструменты ETL, предназначенные для извлечения, преобразования и загрузки данных, также часто имеют возможности влиять на качество данных.
По существу в DW 2.0 есть четыре домена инструментальных средств, обеспечивающих качество данных, как показано на рисунке 18.1:
- Найти – с помощью которых выполняется профилирование и обнаружение (discovery) данных с целью найти аномалии данных и правила;
- Исправить – с помощью которых данные очищаются согласно определенным правилам;
- Переместить – инструменты ETL и ELT, преобразующие данных на пути в хранилище данных;
- Контролировать и делать отчеты – с помощью которых контролируется качество данных и создается отчетность.
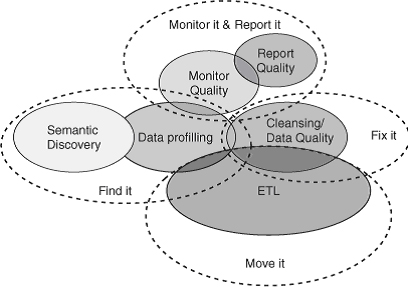
Рисунок 18.1. Функциональные категории инструментов, обеспечивающих качество данных. Согласно Бонни О'Нил (Bonnie O'Neill) и Дерек Штрауса (Derek Strauss)
Во времена хранилищ первого поколения эти четыре домена проявились в качестве отдельных категорий специализированных инструментов. Хотя в хранилищах данных DW 2.0 у многих из этих инструментов все еще есть свои собственные определенные области применения, они подвергаются расширению и частично пересекаются с функциональными возможностями смежных областей. Так же появились новые функциональные категории инструментов, например, инструменты семантического обнаружения (discovery), которые используют нечеткую логику, чтобы обнаружить правила в данных. Некоторые инструменты даже в состоянии проанализировать слабоструктурированные данные. Слияния и приобретения компаний, производящих инструменты, обеспечивающие качество данных, привели к расширению комплектации и возможностей предлагаемых инструментов. На этом фоне, архитекторам DW 2.0 стоит ожидать единый инструментальный набор, который может найти качественные аномалии данных, исправить проблемы качества данных, переместить данные и контролировать и делать отчеты о качестве данных.
Инструменты профилирования данных и обратное проектирование моделей данных
Действительно ли возможно выполнять профилирование данных вручную? Да, это возможно. Вот некоторые из вариантов:
- Организация может нанять дополнительный персонал, чтобы прочесать базы данных и найти повторяющиеся записи и дедуплицировать их. К сожалению это не идентифицирует отношения между файлами или между файлами и системами и будет очень дорого, поскольку новых сотрудников необходимо обучать и контролировать на соответствие бизнес-правилам.
- Другой способ сделать это – написать программы для поиска аномалий данных. Этот вариант, как правило, будет касаться только известных проблем. Это может занять очень долгое время, и нет никакой гарантии, что работа будет эффективной, причина же этого состоит в том, что «мы не знаем, чего мы не знаем».
- Лучший вариант для обнаружения проблем качества данных состоит в том, чтобы использовать инструмент профилирования качества данных.
Сейчас есть много инструментов профилирования данных, помогающих командам, ответственным за качество данных (рис. 18.2). Инструменты облегчают анализ значений данных в колонке, иногда просматривая одновременно множество колонок в таблице, иногда просматривая разные таблицы или даже разные системы, чтобы обнаружить закономерности в значениях выбранных колонок. Эти закономерности могут раскрыть скрытые бизнес-правила, например, каждый раз, когда значение в колонке 1 равно «a», значение в колонке 5 может быть «x» или «y».
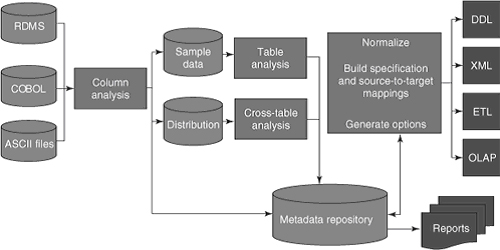
Рисунок 18.2. Компоненты процесса профилирования данных.
Лучшие из этих инструментов профилирования данных идут на шаг дальше. После анализа фактических значений данных в колонках системы инструменты могут предложить нормализованную схему. В действительности происходит вот что: инструмент создает модель данных в третьей нормальной форме, основанную на восходящем анализе («снизу вверх») и абстрагированную от фактических значений в физической базе данных. Эта абстрактная модель данных очень полезный вклад в нисходящий («сверху вниз») процесс моделирования данных, который должен происходить параллельно с разработкой хранилища. Фактически, гарантия, что высококачественная архитектура модели данных разработана для хранилища данных DW 2.0, сильно способствует улучшению качества данных корпоративного хранилища данных.
Типы моделей данных
Итак, какие типы моделей данных составляют хорошую архитектуру DW 2,0? Прежде, чем ответить на этот вопрос, необходимо сделать несколько пояснений. Диаграмма на рисунке 18.3 изображает шесть ячеек столбца «Данные» из структуры Захмана (Zachman framework), представленной в Главе 6.
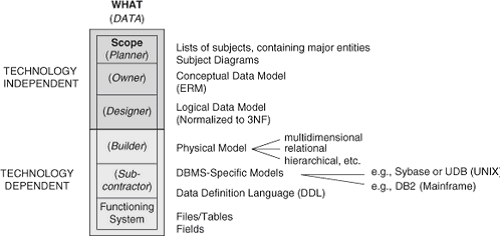
Рисунок 18.3. Типы моделей данных: срез структуры Захмана (Zachman framework).
Три верхние строки означают независимые от технологии представления, и три нижних – зависимые от технологии представления. Верхняя строка обычно состоит из списка объектов данных, которые обобщают представление проектировщика или масштаб (scope) и контекст предприятия. Каждый из объектов данных верхнего ряда может быть разложен на основные сущности данных. Вторая строка изображает представление (взгляд) владельца; главные понятия предприятия представленные в модели данных, часто называемой моделью или диаграммой типа сущность-связь (ER diagram). Третья строка – взгляд проектировщика – содержит логическую модель данных. Обычно это – модель данных в третьей нормальной форме со всеми атрибутами.
Зависимые от технологии представления данных расположены ниже линии, разделяющей 3-ю и 4-ую строки в столбце «Данные» структуры Захмана (Zachman framework). Четвертая строка представляет физическую модель данных. В хранилище данных может быть много физических моделей данных. Могут быть физические модели данных для собственно хранилища, разные физические модели данных для витрин, и еще физические модели данных для других компонентов окружающей среды хранилища. Поэтому модели, представленные на этом уровне, могут включать совокупность реляционных моделей, многомерных моделей и ненормализованных физических моделей данных. Важно отметить, что схемы Звезды и схемы Снежинки – это, фактически, физические модели данных.
Язык определения данных или DDL находится на следующей нижележащей 5-ой строке. Эти инструкции появились в результате создания реальных файлов и таблиц, которые представлены в 6-ой строке.
Диаграмма на рисунке 18.4 представляет различные компоненты, которые составляют ландшафт DW 2.0. Они показаны наложенными на четыре главных сектора DW 2.0: Интерактивный Сектор (Interactive Sector), Интегрированный Сектор (Integrated Sector), Сектор «Первой Линии» (Near Line Sector) и Архивный Сектор (Archival Sector). Каждый уровень хранилища должен позволять обратный аудит до уровня контекста, до концептуального уровню, до логического уровня, до физического уровня, до уровня сборки (build level) и до уровня объектов.
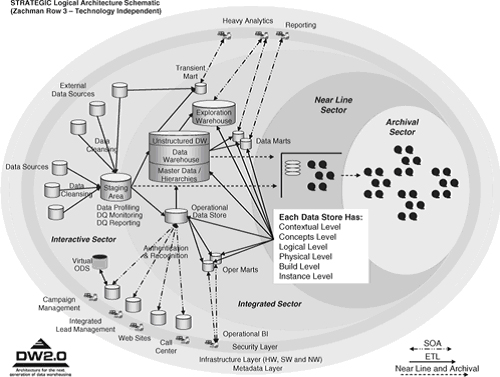
Рисунок 18.4. Ландшафт баз данных DW 2.0.
Хорошая концептуальная модель данных освещает главные понятия бизнеса и как они взаимосвязаны. Хорошая логическая модель данных в третьей нормальной форме содержит и представляет все атрибуты, принадлежащие бизнес сущностям, а также количество и необязательность отношений между этими сущностями. Логическая модель данных дает наибольшее логическое представление бизнеса, и должна стать отправной точкой для третьего типа моделей – физической модели данных.
Физические модели данных для Интегрированного Сектора DW 2.0 (Integrated Sector) могут широко отличаться по своей структуре. Они будут варьироваться от нормализованных и почти нормализованных моделей узлов хранилища данных до моделей типа «звезда» и «снежинка» для витрин данных. Еще другие структуры моделей данных лучше всего подходящие для исследовательских хранилищ данных, хранилищ интеллектуального поиска данных (ODS), оперативных витрин (operational data marts). Данные, перемещаемые в Сектор «Первой Линии» (Near Line Sector), должны быть настолько ближе к структурам третьей нормальной формы, насколько это возможно. Это нормально – реструктурировать данные, поступающие в Архивный Сектор (Archival Sector).
Мультинаправленная трассируемость между моделями данных очень важна для среды данных DW 2.0. Должна быть возможность подниматься от физической модели к логической модели и через нее далее к концептуальной модели. Аналогично, должна быть возможность перемещаться сверху вниз, от концептуальной модели к логической модели данных и далее к физическим моделям данных. Полноценный набор взаимосвязанных моделей будет иметь большое значение в улучшении качества данных на предприятии, увязывая смысл бизнеса и структурные бизнес-правила с физическими экземплярами данных и атрибутами.
И еще раз, Каковы необходимые модели в архитектуре данных DW 2.0? Диаграмма на рисунке 18.5 отвечает на этот вопрос и изображает все необходимые модели данных, используемые в DW 2.0 – хранилище данных следующего поколения.
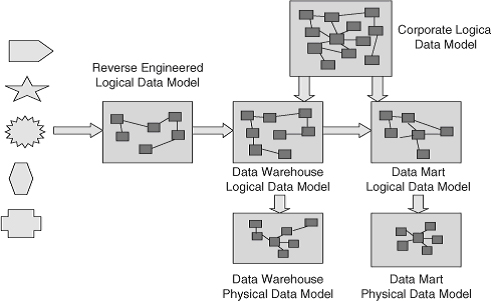
Рисунок 18.5. Типы моделей данных, используемые в хранилищах данных DW 2.0.
С каждой исходной системой осуществляется реинжиниринг для создания логической модели. Корпоративная логическая модель данных, полученная из концептуальной модели, используется в качестве основы для логической модели хранилища данных и логических моделей витрин данных. Физические модели данных, и для хранилища данных, и для витрины данных, получены из соответствующих логических моделей данных.
Отношения между корпоративной логической моделью данных и другими логическими моделями данных заслуживают дальнейшего исследования. Например, отношения между логической моделью хранилища данных и корпоративной логической моделью данных показаны на рис 18.6.
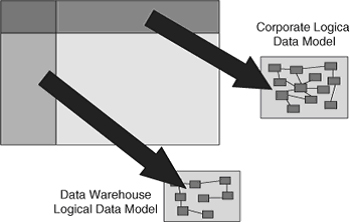
Рисунок 18.6. Корпоративная модель versus логическая модель данных.
Большой прямоугольник на диаграмме представляет ячейку в 3-ей строке 1-ого столбца структуры Захмана (Zachman framework), то есть ячейку логической модели данных (LDM). У каждой ячейки структуры Захмана есть "scope dimension" представленный тонким горизонтальным прямоугольником поверху ячейки LDM, и " detail dimension" представленный тонким вертикальным прямоугольником снизу ячейки LDM. Это хорошая практика – всегда иметь общекорпоративное представление данных, выраженное в корпоративной логической модели данных. Корпоративная логическая модель данных (LDM) охватывает всю сферу предприятия, но не очень подробно.
Модель со всеми атрибутами (полно-атрибутивная) займет слишком много времени и будет очень дорогостоящей. Только главные сущности предприятия и отношения между этими сущностями изображены в корпоративной логической модели данных.
Каждая последующая итерация хранилища данных начинается с логической модели данных, в которую прописываются все атрибуты, необходимые для этой итерации. Красота наличия корпоративной логической модели данных состоит в том, что она позволяет осуществлять поэтапную (инкрементальную) разработку, без ущерба для логического проекта данных (logical data blueprint). Многие проблемы качества данных могут проследить свое происхождение в неадекватном или нескоординированном логическом моделировании данных. Без корпоративной логической модели данных не существует способа сложить кусочки мозаики вместе; каждая последующая итерация разрабатывалась бы в полной изоляции, приводящей к избыточности данных и отсутствию интеграции данных.
Профилирование данных бросает вызов нисходящему моделированию
Пример первый на рисунке 18.7: при профилировании данных в файле были выявлены различные несоответствия. Во время нисходящих («сверху-вниз») сессий моделирования данных сущность под названием «Сторона» («Party») была идентифицирована как индивидуум или организация. У подтипа «Индивидуум» было идентифицировано наличие признака «Пол» («Gender»), с допустимыми значениями «мужчина» и «женщина». Одновременно был использован инструмент профилирования данных, чтобы посмотреть на фактические данные в исходных системах. Инструмент профилирования данных обнаружил, что семь значений фактически использовались в полях с признаком пола. Вскоре стало очевидно, что поле использовалось не только в целях отразить пол человека. Открытие этих разнообразных целей использования атрибута «Пол» и сопутствующих этому структур, может стать основанием для добавления соответствующих сущностей и атрибутов к логической модели данных.

Рисунок 18.7. Пример 1: Найдены несоответствия данных в файлах.
Пример второй на рисунке 18.8 показывает, как противоречия между двумя или более файлами также могут изменить способ построения логической модели данных. Нисходящей сессией моделирования было установлено, что должна быть создана сущность «Продукт» («Product»). Идентификатор Продукта был задан как десятизначный числовой атрибут. Затем были профилированы данные нескольких исходных систем, и стало очевидно, что десятизначным числом был только номер текущего чекового счёта, тогда как номера счетов кредитных карт были 16-значныи числами. После этого логическая модель должна быть исправлена, чтобы отразить 16-значные атрибуты Идентификатора Продукта.
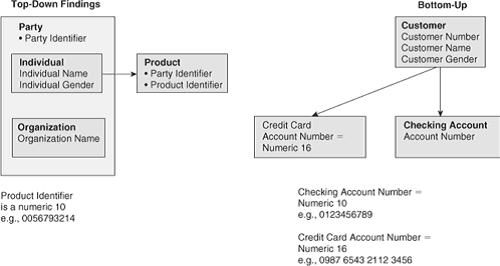
Рисунок 18.8. Пример 2: Найдены противоречия данных между нескольким файлами.
Поэтому передовой опыт показывает, что здоровая комбинация восходящего («снизу-вверх») моделирования данных, движимого инструментами профилирования данных, в сочетании со строгой инициативой нисходящего («сверху-вниз») моделирования данных, будет производить лучшую архитектуру данных для следующего поколения хранилищ данных. Цельная архитектура данных, подобная изображенной на рисунке 18.9, является одним из критических факторов успеха для достижения улучшения качества данных.
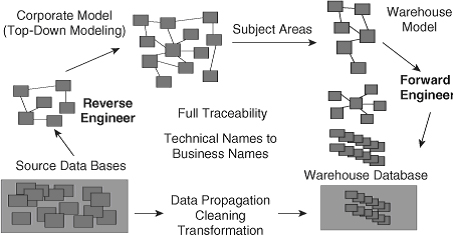
Рисунок 18.9. Компоненты цельной архитектуры данных DW 2.0.
Заключение
Повторное использование является важнейшим фактором успеха для второго поколения хранилищ данных и необходимо сосредоточиться на качестве моделей данных, которые лежат в основе программы. Модели должны точно отражать бизнес и должны повторно использоваться во всех будущих релизах программы.
Основополагающая модель – корпоративная модель данных. Традиционно, эта модель была получена, используя нисходящий подход, методы совместного планирования требований и методы совместного проектирования приложений. Эти методы могут относительно быстро поставить хорошую модель. Проблема с моделями, полученными таким образом, состоит в том, что они основаны исключительно на бизнес правилах, воспринимаемых руководством и старшими аналитиками. В действительности, системы, которые используют эти данные, могут иметь другой свод правил. Это обусловлено тем, что системам часто двадцать и более лет. Недокументированные изменения были внесены в данные и в большинстве случаев людей, сделавших эти изменения, уже нет в организации.
Единственный способ раскрыть, как на самом деле выглядят данные, состоит в том, чтобы провести обратное проектирование данных в абстрагированную логическую модель данных. Хранилища данных первого поколения пытались сделать это в прошлом, но не были доступны инструменты, способные помочь в этом. Сегодня развился новый набор инструментов – инструменты профилирования данных. Эти инструменты являются идеальным помощником в обратном проектировании данных и в восходящем («снизу вверх») построении модели данных. Когда модель создается таким образом, то она основана на фактическом содержании данных, и поэтому уменьшается шанс ошибок и упущений в процессе моделирования данных. Эта, созданная по восходящей, модель используется как вклад в создание модели на основе подхода сверху вниз.
Корпоративная модель данных не единственная модель данных, требуемая для успешной реализации систем бизнес-анализа (business intelligence). Рекомендация состоит в том, чтобы были созданы все модели, определенные в столбце «Данные» структуры Захмана (Zachman framework).