Внедрение Microsoft SQL Server Parallel Data Warehouse с применением подхода Кимбалла

Автор: Уоррен Торнтвейт (Warren Thornthwaite)
Технические рецензенты: Джесси Фонтейн (Jesse Fountain), Барбара Кесс (Barbara Kess), Стюарт Озер (Stuart Ozer)
Опубликовано: Июнь 2011 г.
Применимо к: SQL Server 2008 R2
Краткое содержание:
В настоящем документе описывается, как подход Кимбалла к архитектуре и построению систем хранилищ данных/бизнес-аналитики (DW/BI) работает с Parallel Data Warehouse от Microsoft, и как этот новый продукт можно включить в Вашу DW/BI систему. В начале настоящего документа кратко описан сам подход и его ключевые принципы - это будет интересно читателям, не знакомым с подходом Кимбалла. Затем рассматривается архитектура Parallel Data Warehouse (PDW) и обсуждается ее согласованность с подходом Кимбалла. В последнем разделе даются основные рекомендации и описываются трудности, которые нужно преодолеть при построении или при миграции больших хранилищ данных на систему Microsoft SQL Server PDW. Также здесь описывается, как Parallel Data Warehouse может работать с такими предложениями Microsoft, как SQL Server 2008 R2, Microsoft Fast Track Reference Architecture for Data Warehouse и с новым предложением - Business Data Warehouse, - предоставляя комплексное решение корпоративного класса для хранения данных.
Авторское право
Настоящий документ предоставлен «как есть». Информация и мнения, высказанные в настоящем документе (включая URL и другие веб-ссылки), могут быть изменены без предварительного уведомления. Вы принимаете на себя риск использования настоящего документа.
Примеры, представленные здесь, приведены только для иллюстрации и являются вымышленными. Нет никаких реальных ассоциаций, все совпадения следует рассматривать как случайные.
Настоящий документ не предоставляет никаких юридических прав ни на какую интеллектуальную собственность на продукты Microsoft. Настоящий документ можно копировать и использовать для внутренних целей как справочный материал.
© 2011 Microsoft. Авторские права защищены.
Об авторе
Уоррен Торнтвейт начал свою карьеру в области хранилищ данных/бизнес-аналитики (DW/BI) в 1984 году в компании Metaphor Computer Systems, где он работал восемь лет, внедряя крупные системы DW/BI и управляя консалтинговой организацией. После работы в Metaphor Уоррен стал директором по программам проекта разработки корпоративного хранилища данных (EDW) в Стэнфордском университете. Он оставил Стэнфорд в 1994 году, чтобы стать соучредителем InfoDynamics LLC, консалтинговой фирмы по хранилищам данных. В 1997 году Уоррен присоединился к WebTV, чтобы помочь построить многотерабайтное клиент-ориентированное хранилище данных мирового класса. В 2003 году он вернулся в консалтинг как член группы Кимбалла с Ральфом Кимбаллом.
У Уоррена степень бакалавра (BA) Мичиганского университета в области коммуникаций и магистра делового администрирования (MBA) университета Wharton School в Пенсильвании в области принятия решений. Он соавтор книг Data Warehouse Lifecycle Toolkit («Инструментарий жизненного цикла хранилища данных»), 2-е издание (Wiley, 2008) и Microsoft Data Warehouse Toolkit («Инструментарий хранилища данных Microsoft»), 2-е издание (Wiley, 2011). Он проводит Университетские курсы по Кимбаллу по всему миру и является постоянным участником отраслевых конференций.
Группа Кимбалла стоит у истоков многомерного DW/BI консалтинга и образования, которое ведется в соответствии с нашими самыми продаваемыми книжными сериями Toolkit, Design Tips и статьями. Для получения дополнительной информации посетите сайт www.kimballgroup.com.
Содержание
Введение▲
Еще в 1980-х годах некоторые самые крупные организации столкнулись с тем, что они должны обрабатывать больше аналитических данных, чем способны обработать базы данных больших ЭВМ. Они обратились к системам обработки с массовым параллелизмом (MPP), которые используют стратегию «разделяй и властвуй», распределяя рабочую нагрузку между несколькими машинами и обрабатывая на этих машинах параллельно одну проблему. Эти системы были очень дорогими, но позволяли решить проблему.
В последние несколько лет гораздо больше организаций столкнулись с той же проблемой с данными. Технология MPP изначально была узкоспециализированной, ее ценовой диапазон не позволял ей выйти на широкий рынок. Но сейчас она усовершенствовалась, стала более доступной и подходит для компаний всех размеров. Недавно Microsoft выпустила продукт для баз данных - Microsoft SQL Server 2008 R2 Parallel Data Warehouse (SQL Server PDW), который ориентирован на этот новый, более широкий рынок крупномасштабных хранилищ данных. SQL Server PDW использует программное обеспечение баз данных Microsoft и предварительно настроенные стандартные аппаратные средства, предоставляя функциональность MPP дешевле, чем было возможно ранее.
Основная цель настоящего документа - помочь тем, кто знаком с подходом Кимбалла и столкнулся с ограничениями хранилища данных на односерверных базах данных, понять, как их существующая среда может быть перенесена в среду MPP. В то же время, те, у кого нет опыта использования подхода Кимбалла, ознакомятся с методами и их применимостью к платформе SQL Server PDW. Для этого мы рассмотрим четыре основных темы:
- Краткий обзор подхода Кимбалла
- Архитектура SQL Server PDW с массовым параллелизмом
- Варианты архитектуры хранилища данных предприятия
- Руководство по внедрению SQL Server PDW для построения системы DW/BI на основе MPP
Раздел 1: Подход Кимбалла▲
Есть много неправильных представлений о многомерном моделировании и подходе Кимбалла к построению систем DW/BI. Этот раздел рекомендуется прочитать, даже если Вы уже знакомы с подходом Кимбалла; Вы все равно сможете узнать здесь много нового. Подход Кимбалла к созданию корпоративного хранилища опирается на несколько основных принципов:
- Следование проверенной методологии; мы рекомендуем Жизненный цикл Кимбалла.
- Понимание бизнес-требований, что позволяет бизнесу работать, правильно расставлять приоритеты деятельности и получать ценность бизнеса.
- Разработка таких наборов данных хранилища данных, которые обеспечивают гибкость, удобство использования и высокую производительность.
- Создание и внедрение быстрых, основанных на бизнес-процессах инкрементов внутри инфраструктуры корпоративных данных, известной как матрица шины хранилища данных.
- Разработка и построение архитектуры системы DW/BI, основанной на Ваших бизнес-требованиях, объемах данных и среде ИТ-систем.
- Построение систем переноса данных (ETL) со стандартными компонентами для работы с общими шаблонами проектирования, выявленными в среде аналитических данных.
- Предоставление законченного решения, включающего отчеты, инструменты запросов, приложения, порталы, документацию, обучение и поддержку.
Все эти принципы рассматриваются подробно в книге Data Warehouse Lifecycle Toolkit, 2-е издание (Wiley, 2008). Некоторые принципы мы подробно рассмотрим в настоящем документе.
Следование проверенной методологии: шаги и пути жизненного цикла▲
Жизненный цикл Кимбалла - подробная методология проектирования, разработки и развертывания систем хранилищ данных/бизнес-аналитики, об этом рассказывается в книге Data Warehouse Lifecycle Toolkit, 2-е издание. Схема на Рис. 1 показывает основные этапы жизненного цикла.
Жизненный цикл – это итеративный подход, и каждый проход создает согласованный набор данных и начальный набор соответствующих отчетов и приложений. Каждый проход, как правило, может быть осуществлен за 6-9 месяцев, в зависимости от сложности данных. Построение полной системы DW/BI осуществляется в несколько итераций, каждая из которых загружает новую предметную область данных, подключаемую к общей инфраструктуре корпоративных данных, которая называется матрица шины.
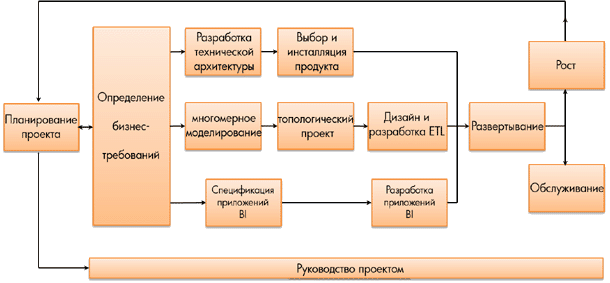
Рисунок 1: Жизненный цикл Кимбалла для DW/BI
Подход Кимбалла начинается с изучения бизнес-требований и поиска лучшего метода добавления ценности для организации. Организация должна согласовать ценность данных до принятия решения о построении хранилища, где будут храниться эти данные. Например, анализ активности при просмотре веб-страниц позволяет хорошо понять поведение и предпочтения Ваших клиентов, что открывает новые пути для более полного удовлетворения их потребностей. Если Вы четко определите и реализуете ценность бизнеса, то бизнес-результат без труда оправдает Ваши инвестиции в SQL Server PDW.
Идеальной отправной точкой для большинства организаций является взятие серии первоначальных интервью, которые помогут собрать и определить приоритеты высокоуровневых бизнес-требований к информации в масштабе предприятия. Результатом будет упорядоченный по приоритетам список бизнес-процессов, которые генерируют данные, и ценные аналитические возможности, которые дают эти данные.
Как только список бизнес-процессов и связанных с ними возможностей определен, и приоритеты расставлены, следующим шагом будет рассмотрение высокоприоритетных бизнес-процессов и сбор связанных с ними подробных бизнес-требований. Этот второй проход по требованиям гораздо больше сфокусирован на понимании специфики необходимых исходных данных, включая их атрибуты, определения, бизнес-правила, качество данных, а также набор аналитики и приложений, которые будут созданы на базе этого набора данных.
После того, как эти подробные требования установлены, Жизненный цикл переходит в фазу внедрения, которая начинается с шагов разработки по трем различным уровням. Верхний уровень, показанный на Рисунке 1, – это технологический уровень. Главной целью здесь является определение функциональности и связанных с ней инструментов, необходимых для удовлетворения выявленных потребностей бизнеса.
Средний уровень на Рисунке 1 - это уровень данных. Первым шагом здесь является определение логической модели данных, необходимой для поддержки аналитических требований. В подходе Кимбалла для этого используется многомерная модель. Как только логическая модель принята, команда может заняться построением целевой базы данных в среде баз данных. Характер физической модели зависит от целевой платформы. Многие продукты для базы данных лучше работают с физическими многомерными моделями, хотя на некоторых платформах может быть оправдано использование более нормализованной модели. Последний шаг работы с данными – создание ETL-системы, которая будет заполнять целевую базу данных по мере необходимости. Создание ETL-системы представляет собой серьезное усилие, часто требующее больше всего ресурсов на начальной стадии проекта.
Нижний уровень на Рисунке 1 связан с BI-приложениями: начальный набор отчетов и анализов, которые будут вырабатывать бизнес-ценность организации. Этот уровень разделен на два этапа: на первом этапе разработки определяется и подробно детализируется небольшой набор важных приложений. Второй этап – фактическая реализация, где формируются эти приложения и отчеты. Для выполнения этого этапа часто приходится ждать почти до конца разработки ETL, когда данные в базе данных становятся доступными. Отметим, что эти отчеты и анализы служат лишь отправной точкой, которая помогает решить важные проблемы. Многомерная модель никаким образом не ограничивается этой подгруппой отчетов.
После того, как эти три уровня внедрения осуществлены, Жизненный цикл выполняет новый проход, развертывая инструменты запросов, отчетов и пользовательские приложения. Этот этап включает в себя различные коммуникации, обучение, создание документации и обеспечение поддержки.
Следующая итерация Жизненного цикла обычно начинается во время развертывания предыдущей итерации, когда бизнес-аналитики и разработчики могут собрать подробные требования для следующих высокоприоритетных бизнес-процессов, создать соответствующую многомерную модель и начать весь процесс заново. Инкрементальный подход Жизненного цикла является фундаментальным, он позволяет в короткие сроки вырабатывать ценность бизнеса при долгосрочном строительстве корпоративного информационного ресурса.
Матрица шины хранилища данных▲
Матрица шины корпоративного хранилища данных – это интерфейс данных для корпоративного хранилища данных. На Рисунке 2 показана упрощенная версия матрицы шины торговой организации в разрезе программы лояльности клиентов.
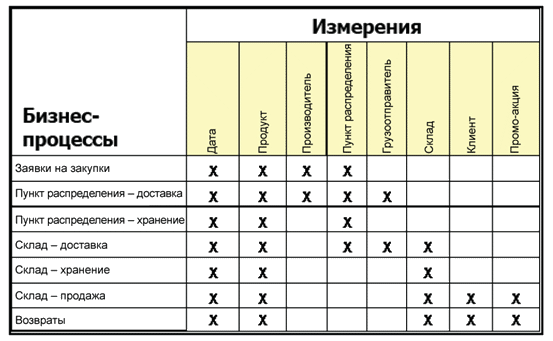
Рисунок 2: Пример матрицы шины
Заголовки строк матрицы шины слева определяют основные бизнес-процессы организации. Удобно думать об этих бизнес-процессах как о цепочке добавленной стоимости в организации. Что делает организация для того, чтобы предоставить клиентам товары и услуги, которые им нужны?
Заголовки столбцов матрицы - это первичные объекты, которые участвуют в этих бизнес-процессах. Типичные примеры - клиенты, счета, продукты, склад, сотрудники, даты. Такие объекты называются измерениями, и они должны быть предварительно интегрированы, чтобы работать со всеми соответствующими бизнес-процессами.
Эта предварительная интеграция называется согласованием, и она включает в себя сложную организационную работу по управлению данными, присвоению стандартных имен, созданию описаний, отображений, иерархии и бизнес-правил, которые будут применяться по всей системе DW/BI. Это, по сути, означает работу, которую выполняет управление основными данными (MDM), работа MDM приносит системе DW/BI огромную пользу. Если системы MDM нет, команда DW/BI должна взять на себя работу по согласованию измерений. После того, как эта работа с определениями выполнена, измерения становятся повторно используемыми компонентами, которые могут быть использованы в каждом соответствующем бизнес-процессе. Очень важно, чтобы согласованные измерения представляли собой инфраструктуру, необходимую для интеграции, при которой результаты двух или более бизнес-процессов могли бы быть объединены в единый результат работы бизнес-аналитики (BI).
Каждая строка в матрице шины представляет собой набор данных бизнес-процессов, который соответствует элементу работы разработчиков системы ETL. Каждому набору данных бизнес-процессов необходим отдельный модуль ETL для извлечения фактов транзакций, их связи с согласованными измерениями и увязывания их воедино в гибкую многомерную модель.
Разработка модели данных▲
Подход Кимбалла к моделированию данных – это прагматичный взгляд на базовую платформу базы данных и последующий выбор физической модели, удобной в использовании, гибкой и производительной, а также возможности обслуживания для конкретной платформы.
Что такое многомерная модель?▲
Почти все многомерные модели представляют собой классические схемы в виде звезды, как показано на Рисунке 3. Числовые измерения («факты») бизнес-процесса сосредоточены в центральной таблице фактов, а контекст измерений [фактов] представлен как набор денормализованных таблиц измерений, которые окружают таблицы фактов. Это ключи, реализующие соединения между таблицами измерений и таблицей фактов, они должны быть анонимными целочисленными ключами. Мы называем их суррогатными ключами.
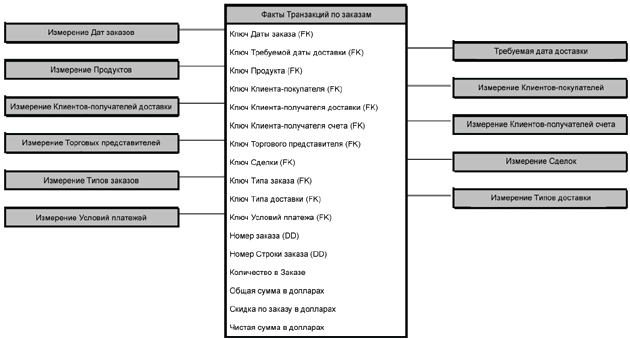
Рисунок 3: Схема-звезда обработки бизнес-процессов
Удобство использования▲
Все специалисты единодушно называют многомерную модель наиболее доступной для пользователя моделью данных в хранилище данных. Например, исследование, опубликованное в 2006 году в журнале Decision Support Systems («Системы принятия решений»), показало, что многомерные модели значительно проще для понимания и понятнее в использовании, чем другие, более нормализованные модели.
Гибкость▲
Существует научная школа, которая призывает к построению нормализованной модели третьей нормальной формы на атомарном уровне хранилища данных. Ее сторонники утверждают, что это дает большую гибкость. Хотя это может быть верно с точки зрения обработки транзакций, важно помнить, что мы строим аналитическую базу данных. Большинство систем обработки транзакций основаны на модели третьей нормальной формы с детализацией транзакций на атомарном уровне, собранных в нормализованные стандартные таблицы фактов. Научная школа третьей нормальной формы придерживается этой модели в качестве основы для корпоративного хранилища данных. Чтобы получить данные в наглядной форме, пригодной для пользователей, эта модель требует дополнительных шагов по преобразованию, часто с участием другого физического слоя витрин данных уровня отделения.
Существует широко распространенное мнение, что многомерные модели основаны на наборе отчетов или анализов и, следовательно, являются менее гибкими. Это неверно, и это никогда не было частью подхода Кимбалла. Нормализованная модель и правильно спроектированная многомерная модель атомарного уровня относительно эквивалентны. Они могут отвечать на точно такой же набор аналитических запросов.
Гибкость частично обеспечивается уровнем детализации информации, собранной в модели. Другим распространенным заблуждением является то, что многомерные модели якобы только обобщают данные. На самом деле, основная цель разработки многомерной модели – всегда собирать данные на самом низком из возможных уровней детализации, так называемом атомарном уровне. Наличие данных атомарного уровня позволяет пользователям сводить данные воедино на любом необходимом уровне обобщения. Любая агрегация, происходящая до включения в корпоративное хранилище данных, означает, что некоторые подробности не будут доступны, что снижает гибкость.
Производительность и обслуживание▲
Многомерная модель сохраняет таблицы фактов на атомарном уровне в их нормализованной форме (путем нормализации таблиц измерений из таблицы фактов) с целью поддержания меньшего размера и более высокой производительности, но сохраняет каждое измерение в денормализованной (плоской) форме. Отметим, что такие плоские таблицы измерений содержат ту же самую информацию, что и полностью нормализованные (метод многомерного моделирования данных «снежинка») многомерные таблицы, но не включают отдельные таблицы и дополнительные ключи, необходимые для завершения процесса нормализации. Многомерная модель упрощает физическую разработку, резко уменьшая количество таблиц и соединений, необходимых для аналитических запросов, что улучшает производительность в большинстве лидирующих на рынке продуктов для баз данных, работающих на одном сервере. На самом деле, все основные продукты SMP-базы данных, включая SQL Server 2008, имеют встроенную оптимизацию производительности, которая использует многомерную модель (дополнительную информацию об этом ищите в Интернете по запросу «оптимизация соединений в звезде»). Также использование многомерной модели на физическом уровне легче в управлении, чем нормализованная модель. Поскольку она уже является многомерной, то чтобы сделать модель пригодной для пользователя, не нужно использовать слой трансляции или отдельные витрины данных.
Как описано в архитектурном разделе ниже, такие платформы с массовым параллелизмом, как Parallel Data Warehouse, работают немного иначе. Данные распределены через сервер по многим независимым узлам запросов. Каждый узел может иметь подмножество фактических данных, которым, возможно, придется присоединиться ко всем измерениям. В SQL Server PDW стандартный подход заключается в репликации всех измерений на каждом узле, так что узел может выполнять локальные соединения, сохраняя таким образом физическую многомерную модель. Однако иногда нормализация и/или распределение очень больших измерений на SQL Server PDW могут быть оправданы в целях экономии времени репликации и для экономии места на каждом вычислительном узле.
Давайте проясним вышесказанное. В идеальном случае для обеспечения гибкости в хранилище загружаются данные атомарного уровня. Для удобства использования пользовательская модель данных будет многомерной, и физическая модель данных также будет многомерной, что обеспечит ее простоту и производительность. В реальном мире все немного по-другому. Мы обнаружили, что на большинстве платформ многомерная модель будет наиболее удобной, гибкой, производительной и наиболее легкой в обслуживании структурой данных для аналитических целей. Компромисс здесь возможен только тогда, когда он требуется для повышения производительности, а пользователи могут быть прозрачно защищены от любых усложнений.
Измерения и факты▲
Как было сказано при обсуждении матрицы шины, измерения - это объекты, которые участвуют в бизнес-процессах организации. Как правило, в модели создается одна таблица для каждого такого объекта. Построение измерения в системе ETL включает в себя присоединение различных нормализованных описаний и иерархических таблиц (которые наполняют атрибуты измерений) и запись результатов в одну таблицу.
На Рисунке 4 – пример типичных связанных с продуктом атрибутов в нормализованной модели.
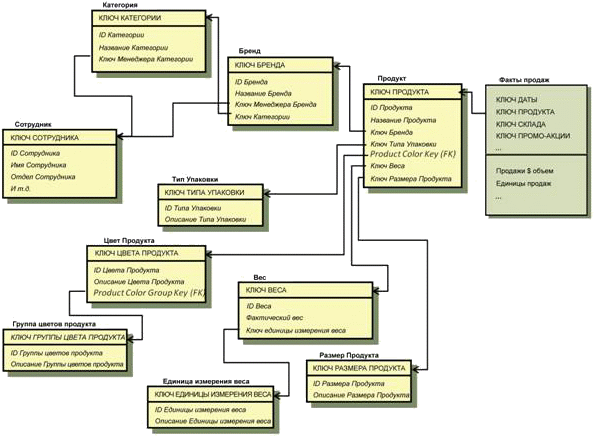
Рисунок 4: Нормализованные исходные таблицы для Атрибутов продукта
Базовая таблица называется Продукт, она соединена с таблицей Фактов продаж на уровне индивидуальных ключей продукта. На основании этого набора таблиц можно осуществлять аналитические расчеты, такие как SUM([Sales $ Amount]) с помощью CategoryName (имя Категории), ProductColorGroupDescr (описание цветовой группы), или любого другого атрибута в любой из нормализованных таблиц, которые описывают продукт. Это возможно, но это не так просто.
В многомерной версии таблицы Продуктов мы на этапе ETL-процесса для создания единой многомерной таблицы Product объединим таблицы, связанные с продуктами, изображенные на Рисунке 4. На Рисунке 5 показано конечное Измерение продукта, основанное на таблицах и атрибутах с Рисунка 4.
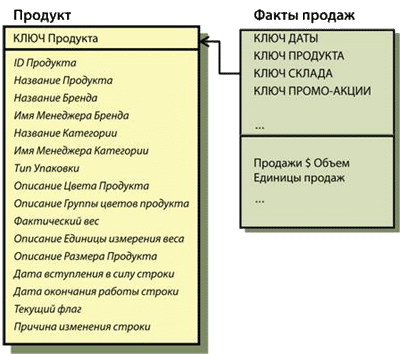
Рисунок 5: Денормализованное Измерение продукта
Очевидно, что рассчитать SUM([Sales $ Amount]) по-прежнему можно как с помощью CategoryName или ProductColorGroupDescr, так и с помощью любого другого атрибута в Измерении продукта, которое включает в себя все атрибуты из нормализованной модели, связанные с продуктом. Обратите внимание, что эти две модели эквивалентны с аналитической точки зрения.
|
Использование инструментов BI для маскирования сложности Большинство BI-инструментов содержат слой метаданных, который может быть использован для отображения нормализованной физической модели, как будто это многомерная модель. Это позволяет обеспечить удобство использования, но имеет свою цену. Во-первых, он доступен только для пользователей, работающих с конкретным инструментом. При любом другом доступе, например, для запросов, встроенных в приложения, нужно будет работать с нормализованной моделью. Во-вторых, этот слой метаданных ставит эти инструменты перед необходимостью создания сложных SQL, которые часто плохо создаются. В этом случае пользователь, как правило, вынужден писать SQL вручную. В-третьих, поскольку базовые физические модели нормализованы, они будут плохо выполнять аналитические запросы по сравнению с многомерной моделью. В-четвертых – стоимость в долларах; эти инструменты достаточно дорогостоящие. |
С появлением многомерной версии удобство использования для разработчиков BI-приложений и особых пользователей повысилось. В этом простом примере десять таблиц, содержащих 12 атрибутов продукта, объединены в единую таблицу. Сокращение количества таблиц в 10 раз для пользователя (и оптимизатора) представляет существенную разницу в удобстве использования и в производительности. Применяя такой подход на практике, по 15 или 20 измерениям Вы можете обнаружить бизнес-процесс, связанный с Продажами, преимущества такого подхода огромны.
Основное различие между двумя подходами заключается в том, что нормализованную версию легче построить, если исходная система уже нормализована, но многомерный вариант проще в использовании и, как правило, лучше работает с аналитическими запросами.
Отслеживание атрибутов изменений с течением времени▲
Каждое аналитическое хранилище данных должно предоставлять средства точного отслеживания изменений атрибутов измерения с течением времени. Отслеживание изменения атрибутов позволяет бизнесу формировать отчет о состоянии окружающего мира в любой момент времени, отвечая, например, на вопрос: «Какие были продажи по регионам 31 декабря прошлого года?» Оно также позволяет вести точный причинно-следственный анализ, сопоставляя значения атрибутов, которые были актуальны, когда произошло событие, с самим событием. Например, по какому почтовому индексу клиент жил, когда покупал определенный продукт два года назад?
С точки зрения простоты и производительности, наиболее эффективный способ сбора таких изменений – добавление строки в измерение, когда атрибуты изменяются, присваивая новый суррогатный ключ, и фиксирование даты вступления в силу и даты окончания для каждой строки. Этот способ обычно упоминается как медленно меняющиеся измерения второго типа. Вы можете видеть такие управляющие столбцы в нижней части измерения Продукта на Рисунке 5.
Хотя отслеживание изменения атрибутов с течением времени увеличивает нагрузку на ETL-процесс, в то же время оно повышает производительность при выполнении запросов пользователей, поскольку объединения фактов и измерений представляют собой простое объединение по эквивалентности по целочисленным ключам. Это также повышает удобство использования, поскольку семантический слой BI не должен обрабатывать более сложные соединения без эквивалентности, со многими столбцами, чтобы получить правильную строку измерения для любого исторического фактического события.
Отслеживание изменений в течение долгого времени является обязательным требованием бизнеса, независимо от базовой модели данных, которую Вы используете. В нормализованной модели есть возможность отслеживать изменения, но сложность хранения нескольких версий в десятках таблиц, связанных с одним измерением, значительно больше, чем работа с изменениями в одной, денормализованной многомерной таблице.
Базовое описание медленно изменяющихся измерений можно найти на www.kimballgroup.com в статье под названием Множество альтернативных реальностей (Many Alternate Realities).
Обсуждения более продвинутых методов отслеживания изменений см. в статье под названием Медленно изменяющиеся измерения не всегда так уж просты (Slowly Changing Dimensions Are Not Always as Easy as 1, 2, 3).
Для получения более подробной информации об отслеживании изменений в нормализованной модели см. Дизайнерский совет № 90 Медленно меняющиеся сущности (Design Tip #90 Slowly Changing Entities) на www.kimballgroup.com.
Производительность зависит от платформы▲
Хотя многомерная модель обеспечивает наилучшую производительность и удобство использования в большинстве стандартных систем DW/BI, она все же годится не для всех. Нужно выбрать правильную базовую физическую структуру данных, обеспечивающую наилучшую производительность на конкретной платформе, не жертвуя простотой использования.
Поскольку мы рассматриваем систему Parallel Data Warehouse, мы обсудим компромиссы в разработке и производительности и, надеемся, найдем лучшее из всех возможных решений.
Раздел 2: Обработка с массовым параллелизмом и Parallel Data Warehouse▲
Рост данных связан с законом Мура (Moore). Так как компьютеры становятся быстрее и мощнее, мы используем их, чтобы обрабатывать больше данных в более сложных приложениях. Традиционные источники, такие, как системы ERP (системы планирования ресурсов в масштабах предприятия), обрабатывают все больше транзакций по мере роста наших организаций. Новые источники, такие, как анализ активности просмотра веб-страниц, мобильные устройства и социальные медиа, создают массивы данных, которые на несколько порядков больше, чем те, с которыми мы имели дело в прошлом.
Мы называем эти большие массивы данных «большие данные». Большим организациям всегда приходилось иметь дело с большими данными, но границы, которые ограничивают большие данные, были расширены мощью компьютеров. Количество данных, с которыми нужно иметь дело, становится проблемой, когда работа в рамках существующей системной среды создает сложности. Для некоторых организаций такой предел может составлять сотни гигабайт. Для более крупных и опытных организаций такая точка перехода больше и составляет десятки терабайт.
Термин «большие данные» сегодня является основным модным словом в ИТ именно потому, что большие данные потенциально обладают большой ценностью. Впрочем, умение извлекать ценность из больших массивов данных в системах транзакций и из социальных медиа-взаимодействий базируется на способности реально управлять данными. Такие компании, как Google и Yahoo!, позволили пионерам таких новых технологий, как MapReduce и Hadoop, помочь им справиться с тем огромным количеством неструктурированных данных, которые они собирают. В то же время, активно растут и развиваются базовые технологии работы с более структурированными большими данными, такие, как системы обработки с массовым параллелизмом (MPP), и базы данных для информации, представленной столбцами.
В большинстве организаций самое сложное при работе с большими данными - решить, как обеспечить крупномасштабный объем транзакций внутри корпоративных систем и сделать его доступным в аналитической среде. Работа с новыми источниками данных, такими, как социальные сети, важна, но не это является сегодня первостепенной проблемой для большинства компаний.
В этом разделе мы начнем с краткого исследования преимуществ и ограничений односерверных систем, актуальных для работы с большими данными. Затем мы рассмотрим подробнее MPP-подход и исследуем архитектуру системы Parallel Data Warehouse.
Сильные стороны и ограничения односерверных систем▲
Большинство «серверов», с которыми Вы работаете – один сервер с общими ресурсами. Каждое ядро процессора может работать с любой частью памяти или жесткого диска, вся память и диск доступны всем ядрам. Такие монолитные архитектуры называют архитектурами симметричной многопроцессорной обработки (SMP). Как показано на Рисунке 6, ядра процессоров соединены с памятью и диском через системную шину. Это совместно используемое соединение работает с высокой скоростью, соединяя процессы и память, обеспечивая обмен данными. Оно проще в управлении, потому что это одно физическое устройство.
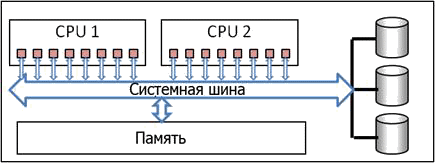
Рисунок 6: SMP-архитектура
Тем не менее, у многопроцессорных систем есть свои ограничения, связанные с обработкой больших данных; эти системы можно масштабировать только до того момента, когда их системная шина не перегружается. Множество процессоров, выполняющих одновременные запросы к данным через системную шину, вызывают «пробки». По мере роста нагрузки системная шина становится узким местом и ограничивает обработку, которую может осуществлять многопроцессорная система. Есть методы, частично решающие эти проблемы путем создания локальных подмножеств процессоров и памяти, но они лишь расширяют имеющиеся ограничения.
Альтернатива обработке с массовым параллелизмом▲
Проверенная временем стратегия обработки больших объемов данных, позволяющая устранить это узкое место, состоит в распределении данных и обработок по разным серверам или узлам, у каждого из которых есть своя собственная память и диск, позволяющие разделять рабочую нагрузку. Этот подход, известный как обработка с массовым параллелизмом (MPP), применялся несколько десятилетий и является основой для многих крупнейших суперкомпьютеров, существующих и сегодня. Исторически из-за своей высокой стоимости и сложности, MPP-системы использовались крупнейшими компаниями и правительственными организациями.
Архитектура с массовым параллелизмом лежит в основе системы Parallel Data Warehouse Microsoft. Parallel Data Warehouse - продукт Microsoft SQL Server, предназначенный для увеличения объемов хранилищ данных с нескольких десятков до нескольких сотен терабайт. Он реализован на основе MPP-архитектуры с использованием комплексной модели, т.е. это предварительно сконфигурированные и оптимизированные аппаратные и программные продукты, поставляемые вместе.
Архитектура SQL Server PDW▲
На Рисунке 7 схематически показана архитектура системы SQL Server PDW MPP. Пользовательский запрос поступает на узел управления, который разбивает SQL на несколько параллельных операций и распределяет их по вычислительным узлам, на которых находятся фактические данные. Специальный модуль, который называется Data Movement Services (сервис перемещения данных), координирует все необходимые перемещения данных между узлами и обрабатывает все функции, которые должны быть выполнены централизованно. Когда работа вычислительных узлов закончена, контрольный узел управляет пост-обработкой и ре-интеграцией результатов для отправки обратно к пользователям.
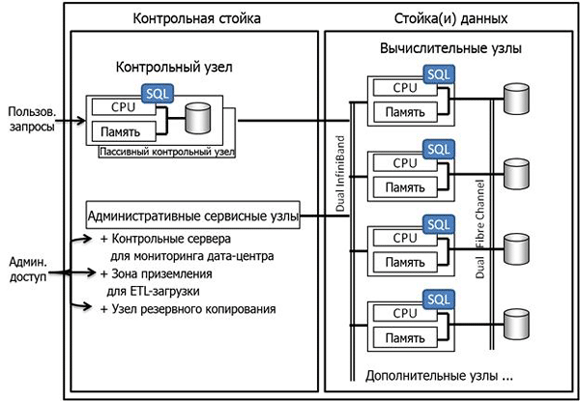
Рисунок 7: Архитектура SQL Server PDW с массовым параллелизмом
Каждый вычислительный узел является отдельным SMP-сервером под управлением SQL Server. Вычислительные узлы в текущих конфигурациях SQL Server PDW - шестиядерные двухпроцессорные системы с 96 ГБ памяти и локальным рабочим местом для tempdb. Они соединены дублированной сетью InfiniBand, обеспечивающей высокоскоростной обмен данными между узлами для межузловых вычислений, известных как «перетасовка данных». Эта сеть также подсоединяет вычислительные узлы к узлам контроля и администрирования, обеспечивая высокоскоростную загрузку данных, извлечение результатов запросов, резервное копирование и другие административные функции.
Дисковые подсистемы на вычислительных узлах работают под управлением сети хранения данных (SAN), они подключены через высокоскоростное двухканальное подключение Fibre Channel. Эта шина данных поддерживает высокоскоростной ввод/вывод и имеет возможности автоматического восстановления. Вычислительные узлы и накопители на дисках физически размещены в одной стойке, называемой стойка данных (data rack).
Есть три вида административных сервисных узлов, которые находятся в одной контрольной стойке вместе с контрольным узлом. К ним относятся:
- Узлы управления (Management Nodes), которые предоставляют DBA (администратору БД) и операциям центра обработки данных интерфейс для доступа и управления общим решением и поддержки внутренней сети системы.
- Узел зоны приземления (Landing Zone Node), куда приходят очищенные данные, и где они подготавливаются перед загрузкой в хранилище данных.
- Узел резервного копирования (Backup Node) и соответствующее место для хранения. Узел резервного копирования осуществляет высокоскоростное интегрированное резервное копирование на уровне базы данных. Он связан с общей стратегией организации и системы по резервному копированию.
SQL Server PDW является крупной системой корпоративного класса со встроенной избыточностью:
- Первичные данные хранятся на RAID1.
- Избыточность в аппаратном обеспечении подразумевает резервные блоки питания, запасные диски, вычислительные узлы, контрольные узлы и серверы управления, предназначенные, в основном, для обеспечения автоматического восстановления.
Масштабируемый комплекс▲
SQL Server Parallel Data Warehouse продается как комплекс для хранилища данных: набор стандартных аппаратных средств и программного обеспечения Microsoft, предварительно настроенного так, чтобы удовлетворять потребности самых разных объемов данных и самой разной производительности. Это оправдано, так как работа по настройке отдельных компонентов, сети и пропускной способности и производительности дисковой подсистемы требует значительных усилий, превышающих те, которые может взять на себя большинство ИТ-магазинов. Когда мы имеем дело с программно-аппаратным комплексом, все компоненты и сетевые подключения тщательно разработаны, настроены и сбалансированы для оптимальной производительности, а необходимое программное обеспечение установлено и настроено предварительно на всех узлах.
Архитектура MPP может быть расширена путем добавления стоек с вычислительными узлами. Базовая система начинается с одной стойки. В конфигурации HP, например, в полную стойку входит 10 узлов, можно добавлять дополнительные стойки с 10 узлами каждая, всего может быть до 40 узлов. Ограничение в 40 узлов введено, скорее, из-за предназначения продукта, это не ограничение конструкции системы. В SQL Server PDW используются возможности резервного копирования и восстановления для упрощения расширения SQL Server PDW: нужно выполнить резервное копирование базы данных, добавить новые стойки, перенастроить систему и затем осуществить восстановление. Восстановление базы данных автоматически перераспределит данные по всем узлам.
Microsoft, предлагая системы SQL Server PDW, работает с несколькими поставщиками оборудования. Компания HP появилась первой на рынке с общедоступным продуктом на момент написания статьи.
Управление данными в SQL Server PDW ▲
При использовании физической архитектуры распределенных узлов с локальными данными большие наборы данных должны быть распределены по узлам так, чтобы они могли поддерживать как процессы обработки данных, так и запросы. Нужно сделать так, чтобы каждый узел и процессорное ядро работали настолько интенсивно, насколько это возможно при каждом запросе. В хранилище данных таблицы фактов равномерно распределены по узлам, так что работа будет у каждого узла.
Обработка на узлах будет эффективной, когда локальные подмножества таблиц фактов можно присоединить к локальным таблицам с измерениями, это можно осуществить, если таблицы измерений реплицированы на всех узлах. SQL Server PDW позволяет указать, какой будет таблица – распределенной или реплицируемой – в момент ее создания, а затем прозрачно управляет размещением соответствующих данных на соответствующих вычислительных узлах во время загрузки.
Применение подхода Кимбалла на SQL Server PDW▲
Как SQL Server PDW согласуется с подходом Кимбалла? Если Вы посмотрите, то увидите, что он вполне соответствует нашим принципам. С его помощью достигается удобство и гибкость, поскольку в большинстве случаев можно построить набор многомерных моделей атомарного уровня с согласованными измерениями. Производительность при этом достигается хорошая, так как нагрузка распределяется по всем вычислительным узлам, а не ограничивается узким местом на одном сервере. В SQL Server PDW дополнительный прирост производительности достигается на уровне узла, поскольку в SQL Server есть функции, поддерживающие многомерные модели, включая оптимизацию «звезда-точка». А поддержка в SQL Server PDW репликации таблиц измерений позволяет выполнять многие обычные сценарии запросов без применения более требовательных операций по «перетасовке» данных.
Раздел 3: Варианты архитектуры корпоративного хранилища данных▲
Задавать вопрос: «Что является лучшей архитектурой для корпоративных хранилищ данных?» – это все равно, что спрашивать: «Где лучше всего жить?» Ответ зависит от того, что важно для Вас. Мы начнем с описания широких требований к хранилищу данных предприятия на уровне, который должен быть приемлемым для всех. Затем мы углубимся в каждое из этих требований, чтобы увидеть, как их можно удовлетворить наилучшим образом.
Требования к архитектуре корпоративных хранилищ данных▲
Конечно, Ваша архитектура зависит от бизнес-требований, а также технических, исторических и политических факторов. Так как бизнес-требования, как правило, специфичны для каждого бизнеса, мы можем начать с широкого списка требований или архитектурных целей, которые будет поддерживать большинство организаций:
- Отличная производительность запросов для пользователей
- Чрезвычайная простота использования
- Гибкость
- Использование и стоимость на уровне предприятия
- Простота обслуживания
Из этих общих целей можно вывести следующие основные компоненты архитектуры корпоративного хранилища данных:
Производительность▲
Основное требование – отличная производительность запросов. Что считать отличным – зависит от ожиданий Ваших пользователей; очевидно, когда это возможно, желательно иметь время отклика в секундах, хотя в некоторых случаях можно считать отличным время отклика в минутах или даже часах, учитывая объемы данных и сложности запросов. Просто чтобы быть ясно, отличная производительность должна быть реализована так, чтобы быть полностью прозрачной для пользователя. У пользователя не должно быть необходимости изучать, какие сводные данные (агрегаты) использовать, в каких витринах данных есть необходимые данные или какой оптимизационный трюк нужно применять.
Простота использования▲
Как мы уже говорили ранее, в целом в отрасли DW/BI систем пришли к согласию относительно того, что многомерная модель является самой простой в работе. Простота использования с точки зрения бизнес-пользователей в конечном счете определяется инструментами BI фронт-энда базы данных хранилища данных. Разработчики или просто любые пользователи, которые пишут отчеты и приложения, непосредственно обращающиеся к базе данных хранилища данных, обычно пишут свой собственный код на SQL. Простота использования с точки зрения разработчика диктуется, в основном, моделью физической базы данных.
Представить многомерную модель в слое BI инструментов метаданных гораздо легче, если лежащая в основе атомарная модель данных уже с измерениями.
Гибкость▲
Гибкость в первую очередь зависит от степени детализации создаваемых таблиц фактов. Если Ваши таблицы фактов используют наибольший уровень детализации, называемый атомарным, Вы всегда сможете агрегировать данные до любого атрибута любого измерения. Таким образом, чтобы обеспечить максимальную гибкость, Ваша DW/BI-система должна охватывать атомарные подробности.
Согласованность измерений также вносит свой вклад в гибкость. Это позволяет пользователям запрашивать данные из таких разных бизнес-процессов, как продажи или запасы, и затем правильно сочетать результаты, используя такие общие атрибуты измерений, как продукт или регион. По сути, это позволяет пользователям сравнивать яблоки с яблоками по всему предприятию.
Обратите внимание, что правильно определенная многомерная модель обладает такой же гибкостью с точки зрения аналитических запросов, как и нормализованная модель, они относительно эквиваленты. Запрос, подсчитывающий итоги продаж по регионам, даст одинаковый ответ в любой из них.
Ресурсы предприятия▲
Настоящий корпоративный информационный ресурс содержит три основных элемента: все данные, доступные всем пользователям; данные, предназначенные для разных бизнес-процессов; единая аналитическая система записи для каждого элемента данных. Давайте рассмотрим эти элементы.
Все данные должны быть доступны всем аналитикам, каким они могут понадобиться, так как все данные нужны в организации всем. Аналитик в отделе логистики должен знать о продажах по географическому признаку и дистрибьюторам. Аналитик в отделе продаж должен знать о продажах по клиентам и регионам. Аналитик в отделе маркетинга должен знать о продажах по продуктам. Это все различные сводные запросы, основанные на одних и тех же атомарных фактических данных о продажах. Не надо думать, что различия между отделами требуют решения в виде разных витрин данных для каждого отдела. Как только Вы ограничите отдел маркетинга сводными запросами по продуктам, они потребуют подробности по клиентам, чтобы проанализировать сегменты потребительского рынка. В какой-то момент каждому аналитику требуется доступ ко всем данным на атомарном уровне.
Данные в разных бизнес-процессах должны быть согласованы, потому что это позволит пользователям быстро и правильно объединять данные из нескольких разных источников по всему предприятию. Данные в корпоративном хранилище данных необходимо интегрировать с помощью корпоративного набора согласованных измерений, определенных в матрице шины. Согласованные измерения и работа, которая уходит на их создание и обслуживание – основной элемент данного ресурса предприятия; согласованные измерения – «подставки», которые поддерживают инфраструктуру корпоративных данных.
Единый источник уменьшает путаницу и потерю времени, которая неизбежна в случае, когда у нас несколько витрин данных с перекрывающимся содержанием данных. Наличие единой аналитической системы учета может подразумевать несколько физических копий для повышения производительности, но это будет компромиссом. Если есть необходимость в нескольких копиях данных, эти копии должны быть построены из одной, центральной базы данных хранилища данных. Хотя, возможно, в аналитических целях можно осуществлять преобразования, но если одни и те же таблицы и атрибуты находятся в разных местах, они должны быть описаны с теми же именами и определениями во избежание ошибок и недоразумений.
Крупномасштабные серверные возможности таких продуктов, как SQL Server PDW, позволяют создать настоящий корпоративный информационный ресурс: единая версия фактов, не требующая дополнительного времени, ресурсов и технического обслуживания, необходимого для копирования данных на несколько витрин данных.
Обслуживание▲
Чем проще архитектура, тем легче будет работать с ней и тем проще ее обслуживать. Единая, высокопроизводительная база данных с детализацией на атомарном уровне и возможностью быстрого обобщения, основанная на многомерной модели – самый простой способ реализовать самые широкие требования предприятия.
Архитектурные компромиссы▲
Возможно, Вам придется настраивать свою собственную идеальную архитектуру системы DW/BI, если она не удовлетворяет требования предприятия. К компромиссам чаще всего приходится прибегать в отношении производительности, если идеальная архитектура не работает, то она не так уж идеальна. Но прежде чем мириться с низкой производительностью, важно убедиться, что Ваша идеальная архитектура правильно настроена. Если система все еще не работает, скорее всего, Вам необходимо пойти на компромисс распределения данных.
Настройка производительности▲
Производительность зависит от платформы. В системах DW/BI есть два стандартных инструмента - индексы и агрегаты (составные данные). Эти инструменты сильно различаются в разных платформах и продуктах БД. Например, рассмотрим вариант, когда в среде SMP запрос, который запрашивает общие объемы продаж за последние 5 лет, может занять очень много времени. В этом случае имеет смысл единовременно создать составные таблицы на этапе ETL-процесса, которые можно будет использовать снова и снова для ответа на запросы сводного уровня. (Заметим, что для того, чтобы сохранить простоту использования, такие составные таблицы должны быть прозрачными для пользователя.)
Однако среда MPP предлагает третий инструмент для улучшения производительности: параллельная обработка. Распределение запросов по нескольким узлам может позволить обрабатывать запросы сводного уровня на лету. Это существенно упрощает дизайн, настройку и обслуживание индексов и сводных данных. В архитектуре параллельной обработки можно положиться на брутфорс, что обеспечивает отличную производительность запросов в среде MPP.
Распределенная обработка▲
Если настройки производительности или параллельной обработки не достаточно, можно создать отдельные подмножества хранилищ данных и размещать их на подчиненных серверах. Эти витрины данных могут охватывать определенные отделы; данные зачастую ограничиваются несколькими предметными областях и обобщаются. (Если витрины данных будут содержать атомарные данные всех бизнес-процессов, Вы вернетесь туда, откуда начали - к корпоративному хранилищу данных.) С точки зрения производительности идея заключается в том, чтобы передать подмножество пользователей и запросов на выделенную платформу. Это грубая форма распределенной обработки, и, вероятно, она менее эффективна, чем просто добавление еще одной стойки к машинам SQL Server PDW, где она могла бы быть использована всей организацией по мере необходимости.
Бывает, когда такая распределенная стратегия оправдана. Некоторые данные могут быть полезны или интересны только небольшому аналитическому сообществу. Другие данные могут быть конфиденциальными и строго требовать ограничений физического доступа. В некоторых случаях желание сделать отдельный сервер может быть организационным - определенный отдел может настаивать на том, чтобы хранить свои данные на собственном сервере. Как это будет описано в разделе о внедрении, у Вас могут уже быть витрины данных с работающими в них расширенными отчетами и приложениями. В этом случае гораздо проще изначально заполнить эти нижестоящие витрины из SQL Server PDW, а не переписывать отчеты и приложения, чтобы они работали непосредственно с SQL Server PDW.
В таких случаях SQL Server PDW может выступать в качестве центрального источника для распределенного хранилища данных. В SQL Server PDW есть функция удаленного копирования таблицы (Remote Table Copy), которая быстро передает таблицы этим нижестоящим SQL Server системам. Целевые системы должны быть физически расположены достаточно близко к SQL Server PDW, чтобы они могли подключаться к сети InfiniBand, так как они - часть высокоскоростного элемента. Если нижестоящие системы разработаны на основе архитектуры Microsoft Fast Track, скорость передачи данных может быть значительной. Нижестоящие системы также могут быть витринами данных, работающими под управлением SQL Server 2008 или более новой версии. Для этого годятся новые комплексы HP Business Data Warehouse, оптимизированные под SQL Server 2008 R2, и HP Business Data Warehouse, BI-комплекс, оптимизированный под SQL Server 2008 R2.
Расширенная аналитическая функциональность▲
Есть несколько способов расширить основную функциональность хранилища данных в рамках платформы SQL Server. Система оперативного анализа (OLAP) SQL Server Analysis Services позволяет использовать более продвинутую аналитическую функциональность и позволяет достичь лучшей производительности при работе со сложными запросами. Служба Analysis Services по сбору данных дает прогнозный анализ, который позволяет облегчить серверу параллельной обработки получение ценных закономерностей и взаимосвязей из огромного количества транзакций.
Аналитические витрины▲
Большинство организаций, работающих с системами DW/BI много лет, пошли дальше создания простой отчетности. Они построили комплекс аналитических приложений с использованием прогнозной аналитики и разноплановых панелей мониторинга, которые задействованы в ключевых показателях производительности в масштабах предприятия. Создать запросы, которые заполнят эти расширенные BI-инструменты, может быть непросто, так как нужно сделать несколько проходов по нескольким таблицам фактов на разных сводных уровнях. В этих условиях, как правило, легче создать дополнительные наборы данных, предварительно их интегрировать и рассчитать большую часть аналитики.
Это может быть сделано либо через таблицы в SQL Server PDW, либо с помощью отдельной витрины данных OLAP. Такие типы рассчитываемых наборов данных в реляционном хранилище данных часто называют снимком таблицы фактов или накопительными таблицами фактов. Обычный снимок таблицы может включать инвентаризацию остатков на определенный момент времени или остатки на счетах в финансовых службах в конце месяца.
Вариант с OLAP лучше, потому такие базы данных OLAP, как SQL Server Analysis Services, предназначены для выполнения более сложных аналитических расчетов и позволяют улучшить производительность за счет создания и управления сводными данными (агрегатами). Язык, используемый для доступа к службам Analysis Services, называется языком многомерных выражений (MDX). Он был создан для поддержки аналитики. В него встроены такие функции работы с датами, как «текущий месяц», «с начала года», «предыдущий год». Он также может работать с иерархиями, например, с переходами от района к области и затем к стране.
В любом случае ядро хранилища данных SQL Server PDW будет служить основой данных, и такие аналитические таблицы или витрины будут построены на основе его очищенных и согласованных данных.
В некоторых сочетаниях функциональности службы Analysis Services также можно использовать как слой управления запросами для SQL Server PDW в режиме, известном как реляционный OLAP (ROLAP). В этом режиме Analysis Services получают данные непосредственно из SQL Server PDW во время запроса, а не используют предварительно загруженную в Analysis Services базу данных OLAP. Этот режим также предоставляет полный доступ к расширенным аналитическим возможностям, предлагаемым языком многомерных выражений (MDX). Пользовательские запросы из слоя инструментов BI направляются в службы Analysis Services, переводятся в SQL и направляются в базу данных SQL Server PDW.
Сбор данных▲
Функциональность сбора данных от Microsoft позволяет управлять интересной прогнозной аналитикой, включающей прогнозирование, механизмы выработки рекомендаций, сегментацию клиентов. Сам компонент сбора данных является функцией службы Analysis Services, он работает на сервере Analysis Services.
Parallel Data Warehouse может быть источником данных, который предоставляет информацию движку по сбору данных, таким образом допуская модели, основанные на огромных объемах деталей на уровне транзакций, хранящихся в SQL Server PDW, в сочетании с хорошо атрибутированными измерениями. Создание набора входных данных часто является самой сложной частью процесса сбора данных, потому что такие наборы данных, как правило, подразумевают многократные полнотабличные поиски, определяющие характеристики и изменения характеристик с течением времени.
BI отчетность и приложения▲
Один из первых принципов подхода Кимбалла, указанный в первом разделе данного документа, заключается в предоставлении полного DW/BI-решения. Это включает в себя предоставление доступа пользователям к специальным обзорам и BI-отчетам и приложениям, которые создают ценность для бизнеса, определенную в процессе сбора требований. Microsoft предлагает набор отчетных и аналитических инструментов в рамках продуктов для DW/BI, и Parallel Data Warehouse – полноправный участник этой экосистемы. Отчеты и запросы Reporting Services и Report Builder и сторонние инструменты бизнес-анализа могут получать данные из SQL Server PDW также, как и из любой другой базы данных SQL Server. То же верно и для таких инструментов Microsoft Office, как Microsoft Excel и Microsoft PowerPivot. Все эти методы доступа для пользователей могут размещаться в Microsoft SharePoint, а предоставляться могут с помощью BI-портала. Приложения .NET могут получать доступ к SQL Server PDS через драйверы ADO.NET, а сторонние средства могут взаимодействовать с SQL Server PDW с помощью OLE DB и ODBC. Все необходимые драйверы включены в продукт PDW Server SQL.
Архитектура корпоративного хранилища данных - резюме▲
Таким образом, вышеуказанные цели приводят нас к следующим компонентам идеальной архитектуры корпоративного хранилища данных:
Таблица 1: Компоненты и цели архитектуры
| Компоненты | Достигаемые цели |
|---|---|
| Атомарные данные | Гибкость, ресурсы предприятия |
| Единый склад данных | Ресурсы предприятия, удобство обслуживания |
| Параллельная обработка и/или сводные данные (агрегаты) | Производительность |
| Многомерная модель | Удобство использования для всех типов пользователей |
| Согласованные измерения | Ресурсы предприятия, интеграция |
| Отслеживание изменений атрибутов | Ресурсы предприятия, простота использования, точность архивов |
Здесь упоминается отслеживание изменений атрибутов, хотя это скорее функция ETL-процессов, так как это является обязательным с точки зрения бизнеса, а простота реализации зависит от базовой модели данных. Поэтому мы перечислили отслеживание как часть ядра архитектуры хранилища данных. Графическая модель этой архитектуры может быть представлена следующим образом:
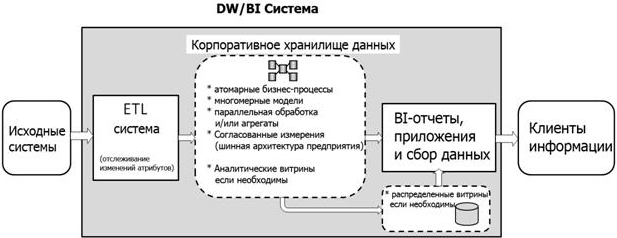
Рисунок 8 - Высокоуровневое корпоративное хранилище данных в системной архитектуре DW/BI
Parallel Data Warehouse занимает в этой архитектуре центральное место. Во многих случаях PDW может предоставить решение без компромиссов, с единым набором данных атомарного уровня, хранящихся в многомерных моделях, использующее параллельную обработку данных для обеспечения высокой производительности и организованное как ресурс предприятия на основе матрицы шины и согласованных измерений. SQL Server PDW в случае необходимости может также взять на себя выполнение многих процессов ядра ETL, эту функцию мы обсудим в разделе внедрения.
Раздел 4: Построение корпоративной системы DW/BI с SQL Server PDW▲
Большинство читателей рассматривают Parallel Data Warehouse как уже имеющееся хранилище данных и ищут способы, которые помогут справляться с растущими объемами данных и требованиями производительности. Многие крупномасштабные системы хранилищ данных/бизнес-аналитики следующего поколения эволюционировали из существующих систем DW/BI, которые разработаны на основе подхода Кимбалла. В данном случае переход к SQL Server PDW будет простым.
В этом разделе мы рассмотрим основные шаги по преобразованию существующего хранилища данных Кимбалла на SMP-основе в сервер Parallel Data Warehouse и опишем SQL Server PDW с точки зрения администратора БД. Мы также изучим дополнительные роли, которые может выполнять SQL Server PDW, включая работу в качестве центрального источника или хаба в распределенном окружении хранилища данных, работу в качестве движка ETL-преобразований и в качестве платформы для предоставления аналитических данных в режиме реального времени.
Подготовка и установка▲
Система SQL Server PDW должна находиться в центре обработки данных и располагаться по крайней мере на двух стойках, поэтому до того, как приедет грузовик с оборудованием, нужно распланировать с группой управления сервером размещение оборудования. Так как система использует InfiniBand, то любые другие серверы, которым Вы хотите предоставить возможность использовать быструю передачу данных, должны обладать соединением InfiniBand и располагаться достаточно близко к серверу SQL Server PDW, так как есть определенные ограничения по длине кабеля.
Инсталляция, выполняемая поставщиком оборудования, обычно входит в условия покупки и занимает несколько дней, в зависимости от обстоятельств.
При планировании нужно учитывать Вашу общую стратегию преобразования. Диапазон преобразований варьируется от прямого преобразования существующего хранилища данных до полной переработки архитектуры системы в рамках миграционного процесса. В этом разделе мы сосредоточимся на прямом преобразовании, а переработку архитектуры обсудим ниже.
Миграция данных▲
Следующим шагом после того, как машина запущена и работает, будет создание новой базы данных, экземпляров целевых объектов и их свойств, копирование данных. База данных Parallel Data Warehouse – это движок SQL, но она немного отличается от базы данных SQL Server, основанной на SMP. Отличия в основном из-за того, что это параллельная система обработки, и многое там работает по-другому. Некоторые функции подразумевают последовательную обработку, что невозможно в параллельной среде. А другие функции, такие, как распределение данных по узлам для параллельного выполнения, не существуют в среде SMP.
При преобразовании существующей SMP-базы данных SQL Server в SQL Server PDW можно использовать инструмент, который создала в этих целях команда Microsoft PDW. Он создает таблицы, настраивает индексы и разбиения, предлагает стратегии распределения для таблиц фактов, выявляет такие проблемы, как типы данных, не имеющие прямых аналогов в SQL Server PDW, формирует фактические BCP-скрипты (скрипты копирования данных) для копирования данных из SQL Server и загружает скрипты для загрузки данных в SQL Server PDW.
Если существующее хранилище данных работает не под управлением SQL Server, начальная миграция данных все равно довольно проста, если есть четкий набор многомерных моделей. Миграция не должна занять больше нескольких часов и зависит от количества таблиц.
Существенное преимущество системы SQL Server PDW с точки зрения администратора базы данных – упрощение управления физическими данными. Физическое расположение данных, включая файловые группы, распределение данных по дискам, LUN (логические номера устройств) и расположение tempdb устанавливается и работает автоматически, в рамках ядра системы SQL Server PDW.
При перемещении в окружение с массовым параллелизмом нужно сделать одно высокоуровневое физическое решение: определить, как именно следует разделить таблицы по узлам. Есть два основных способа физически хранить таблицы в SQL Server PDW: через репликацию или через распределение. Определение CREATE TABLE включает в себя параметр распределения.
Реплицируемые таблицы▲
Реплицируемая таблица выглядит как единая таблицы для всех, кто обращается к SQL Server PDW, но на самом деле она реплицирована по всем вычислительным узлам на сервере. То есть на каждом узле есть свой экземпляр таблицы.
Реплицирование таблиц нужно для повышения производительности с помощью локальных копий данных на каждом узле для поддержки локальных соединений. Реплицируемые таблицы обычно используются для измерений и справочных таблиц, для обеспечения локальных соединений с таблицами фактов.
Реплицируемые таблицы управляются системой прозрачно. Для администратора базы данных синтаксис CREATE TABLE довольно прост:
CREATE TABLE Customer (
CustomerKey int NOT NULL,
Name varchar(50),
ZipCode varchar(10))
WITH
(DISTRIBUTION = REPLICATE);
Если условие DISTRIBUTION (РАСПРЕДЕЛЕНИЕ) опущено, то по умолчанию используется значение REPLICATE (РЕПЛИКАЦИЯ).
Распределенные таблицы▲
Ряды распределенной таблицы распределены по всем узлам настолько равномерно, насколько это возможно. Каждой строке приписывается распределение - т.е. место хранения на узле. На каждом вычислительном узле есть восемь распределений, каждое со своими дисками. Другими словами, здесь не создаются копии; каждая строка в таблице-источнике копируется только в одно распределение на одном вычислительном узле. Строки отображаются на распределение с использованием хэш-функции по столбцу таблицы.
Цель распределения - повысить производительность за счет максимизации параллельности обработки. Таблицы фактов, как правило, самые большие таблицы в хранилище данных, и они обычно распределены.
На Рисунке 9 показан упрощенный вариант распределения таблицы фактов продаж по восьми вычислительным узлам на основе столбца Клиентский Ключ (CustomerKey).
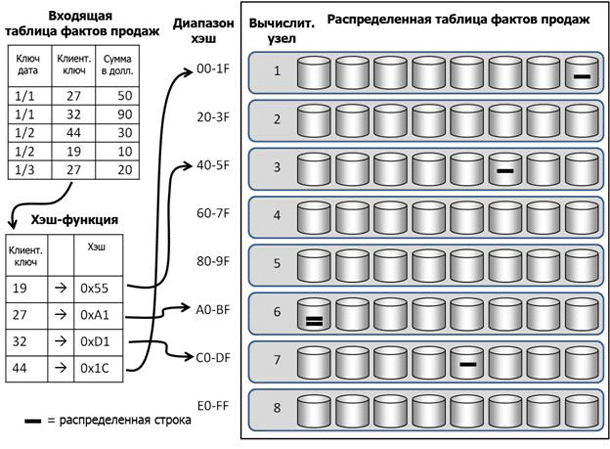
Рисунок 9: Распределение таблицы фактов
Клиентский Ключ каждой строки Входящей таблицы фактов продаж (Incoming Sales Fact Data) в верхнем левом углу проходит через хэш-функцию. Хэшированное значение отображается на одно распределение на одном узле. Например, строка для клиентского ключа 44 хэшируется в 0x1C, что указывает на последнее распределение первого вычислительного узла. Вот DDL (определение) для распределенной таблицы, показанной на Рисунке 9:
CREATE TABLE SalesFact (
DateKey INT NOT NULL,
CustomerKey INT,
DollarAmount MONEY)
WITH
(DISTRIBUTION = HASH(CustomerKey));
То есть колонку распределения определяет ключ. Если несколько клиентов обеспечивают значительный процент продаж, использование клиентского ключа приведет к дисбалансу в распределении данных. Тогда 1-2 распределения будут, в конечном итоге, содержать больший процент данных. Такой дисбаланс называется расфазировка данных. Одно или несколько распределений с количеством строк, превышающем среднее количество более чем на 10%, может вызвать проблемы, а разница более чем на 30% приведет к снижению производительности. Это важно, потому что для завершения любого запроса нужно ожидать завершения работы по всем узлам, и узел со значительно большим объемом данных потребует больше времени, чем другие, когда обрабатываются запросы, включающие такие расфазированные данные.
Основным критерием для выбора правильного столбца для распределения является высокая мощность ключа (т.е. значительное количество разных элементов) и четность количества строк. Есть и другие соображения о выборе столбца распределения. Например, было бы не очень правильным выбирать столбец, который в пользовательских запросах часто принимает какое-то одно значение. Если пользователи часто создают запросы, ограниченные одним днем, то столбец КлючДата (DateKey) не подходит для распределения, потому что все строки за один день будут в одном распределении. Есть и другие факторы, которые нужно учитывать при выборе ключа распределения, такие, как распределение нескольких таблиц фактов, которые, возможно, должны быть объединены вместе для предоставления какой-либо аналитики.
Параллельные вычислительные мощности системы SQL Server PDW позволяют протестировать выбранный ключ распределения. Нужно выбрать ключ распределения, загрузить таблицу и выполнить какие-нибудь распределенные запросы и представительный набор пользовательских запросов по этому ключу. Если возникнут проблемы, Вы сможете создать другую версию распределенных таблиц, отличную от первой версии, используя инструкцию CREATE TABLE AS SELECT и изменив столбец в условии DISTRIBUTION = HASH (). За счет параллельной обработки это происходит, как правило, существенно быстрее, чем можно было бы ожидать. Конечно, чтобы создать несколько копий больших таблиц фактов, необходимо достаточно места, даже если они всего лишь экспериментальные.
Работа с очень большими измерениями▲
Как мы уже говорили, измерения в хранилище данных SQL Server PDW почти всегда реплицируются. Как правило, таблицы измерений объемом (без сжатия) 5 Гб или меньше должны быть реплицированы. На каждом узле должно быть достаточно места для репликации таблицы. Измерение в 5 Гб можно сжать до 2 Гб, что потребует в общей сложности 20 Гб, когда оно реплицируется на стойку с 10 узлами. Кстати, сжатие происходит автоматически и является обязательным в SQL Server PDW.
Чтобы иметь примерное представление о размере таблицы измерения на предмет ее реплицирования, можно сказать, что измерение наподобие показанного на Рисунке 5 с 500-байтным размером строки (без компрессии) может разрастись до 10 миллионов строк, прежде чем потребуется рассмотреть и другие варианты.
Измерения больше 5 Гб (не сжатые) не являются чем-то невозможным, особенно при работе с большими данными. Если у Вас есть измерение, которое превышает порог репликации, то в параллельном окружении есть два основных варианта действия: распределение или нормализация.
Распределение больших измерений требует столько же вычислительной мощности для таблицы фактов. Однако, если строки, необходимые для выполнения запроса, не находятся на том же узле, что и соответствующая таблица фактов, нужные ключи должны быть «перетасованы» по узлам. SQL Server PDW позволяет быстро перемещать данные, когда это необходимо в рамках выполнения запроса, но работа с локальными данными всегда быстрее.
В некоторых случаях можно распространять измерение, используя тот же суррогатный ключ, что и в таблице фактов. Этот общий ключ распределения позволит оставить соединения локальными, так как требуемые строки измерения будут находиться на том же узле, что и соответствующие строки таблицы фактов.
Второй вариант - нормализация очень больших измерений, что позволит уменьшить их размер и сделать их репликацию менее обременительной. Если измерение продуктов, показанное на Рисунке 5, содержит 10 миллионов строк, то это потребует около 2 ГБ (в зависимости от ширины столбцов и степени сжатия), что приближается к потолку репликации. Нормированная таблица продуктов, показанная на Рисунке 4, потребует лишь около 325 Мб для 10 миллионов строк. Очевидно, что 325 Мб проще скопировать на 10 или 20 узлов, чем 2 Гб.
А если большинство запросов к большому измерению возвращает или относится только к нескольким столбцам, рассмотрите возможность создания консольного измерения. Т.е. основное измерение будет содержать часто используемые столбцы. А остальные столбцы помещаются в отдельную таблицу – такие таблицы называются консольными – с тем же суррогатным ключом. Основные измерения могут быть реплицированы и будут локально соединяться с таблицей фактов. Запросы, которые требуют менее распространенные атрибуты, могут собрать их в запросе с соединением с реплицированным консольным измерением. Это простой способ вернуться в рамки, в которых работает репликация без нормализации измерения целиком.
Можно оградить пользователей от сложностей нормированного или консольного дизайна, предоставляя ракурсы, которые снова объединяют нормализованные столбцы в одно измерение. Проверьте эти ракурсы, убедитесь, что они не оказывают негативное воздействие на производительность.
Возможно, Вы слышали, что для систем MPP нормализация необходима. Чтобы объяснить это требование, обратимся к историческому контексту. Ранние системы MPP обладали более жесткими пространственными ограничениями, низкой пропускной способностью между узлами, а хранение было более дорогостоящим. Это привело к тому, что нормализация измерений производилась по умолчанию для того, чтобы уменьшить объем данных, реплицируемых на каждом узле. Поставщики MPP обходили молчанием эти причины, утверждая, что использовать нормализованную модель нужно, так как это «отраслевой стандарт» для корпоративного хранилища данных. Не обманывайте себя этой обратной логикой. Нормализация измерений – это проектное решение MPP, позволявшее повысить производительность за счет уменьшения объема данных, которые реплицируются и хранятся на узлах. Необходимость нормализации измерений в реализации SQL Server PDW встречается на сегодняшний день редко.
Дополнительное DDL (определение)▲
Есть несколько дополнительных проектных решений для определения таблиц хранилища данных. Как правило, в системе MPP гораздо меньше индексов, потому что они не нужны. Поэтому используйте кластерные индексы там, где это оправдано. В большинстве случаев кластерный индекс создается для суррогатного ключа таблиц измерений, и в том же столбце, который используется для разбиения таблиц фактов. Используйте некластеризованные индексы с большой осторожностью. Во многих случаях они не нужны в силу того, что они усложняют обслуживание и замедляют процессы загрузки, занимают место и тем самым влияют на скорость обработки.
Таблицы фактов могут быть сегментированы по тем же причинам, по которым они разделяются на многопроцессорных системах, например, для реализации «плавающего окна» или загрузки фрагмента, использующего операцию SWITCH. Сегментирование в SQL Server PDW принципиально проще, потому что оно полностью указывается как часть DDL создания таблицы, а не через отдельную схему и функцию сегментирования.
Создание ETL-системы для загрузки целевой модели▲
После того, как таблицы в SQL Server PDW определены, следующим шагом будет загрузка в них данных. Начальный перенос данных, скорее всего, будет подразумевать использование скриптов для массового копирования архивов хранилища данных в SQL Server PDW. Затем, если Вы используете SQL Services Integration Server, Ваша ETL-система должна работать с SQL Server PDW также, как она работала с предыдущим хранилищем данных. Например, в SQL Server PDW есть собственные соединения для источника и назначения, которые можно использовать в пакетах Integration Services. Однако есть несколько отличий, которые повлияют на Вашу ETL-систему.
Назначение суррогатного ключа▲
Свойство IDENTITY с типом «целое» не поддерживается в SQL Server PDW, потому что строки распределенной таблицы будут вставляться в разные узлы. Отслеживание инкрементального ID по нескольким узлам в параллельной обработке резко замедлит любой процесс вставки. Если для назначения измерениям суррогатных ключей используется свойство IDENTITY, нужно будет либо в ETL-процессе сохранить в таблице значения суррогатного ключа и назначать их инкрементально, либо в инструкции INSERT использовать функцию ROW NUMBER ACROSS.
Поиск только кэшированной информации▲
Если Вы используете преобразования службы Integration Services Lookup в существующих ETL-пакетах, убедитесь, что выбран пункт Полное кэширование (Full Cache) в разделе Режим кэша (Cache mode) при запросах SQL Server PDW, когда предварительно заполняется кэш. Использование преобразования Lookup для выполнения операции SELECT без кэширования по строкам входящего канала службы Integration Services работает с SQL Server PDW неэффективно.
Зона приземления▲
В системе SQL Server PDW есть отдельный сервер постадийной работы - часть контрольной панели (стойки) - которая называется «зона приземления». Входящие данные из Integration Services или загрузчика SQL Server PDW (DWLoader.exe) проходят через «зону приземления» до распределения по вычислительным узлам на постоянное хранение. «Зона приземления» быстро читает входящие строки из файлов или служб Integration Services и отправляет их на вычислительные узлы циклически, используя модуль, который называется Data Movement System (DMS, система перемещения данных), которая управляет перемещением данных внутри системы. На каждом вычислительном узле DMS будет хэшировать строки и отсылать их обратно на DMS того узла, на который они переносятся. DMS этого узла вставит эту строку в промежуточную таблицу, где может применяться любая сортировка и индексирование. На последнем шаге применяется SELECT INTO, чтобы скопировать данные из промежуточной таблицы в целевую таблицу. Все это происходит прозрачно для пользователя и находится под управлением системы.
Этот поток позволяет осуществлять параллельную загрузку данных и сводить к минимуму обработку, выполняемую непосредственно на «зоне приземления».
Одно из преимуществ параллельной обработки состоит в том, что загрузку можно осуществлять параллельно с тем, как пользователи выполняют запросы к данным. Процессы загрузчика получают более низкий приоритет, поэтому они мало влияют на запросы пользователей. Это означает, что можно обрабатывать вчерашнюю загрузку, не ограничивая доступ пользователей. Это также означает, что можно выполнять оперативную загрузку данных, предоставляя доступ к текущим данным там, где это необходимо.
Совместимость с Transact-SQL▲
SQL Server PDW использует свой собственный вариант SQL с расширениями, необходимыми для поддержки параллельной обработки. Некоторые функции продукта SMP SQL Server не реализованы в SQL Server PDW. Некоторые были не реализованы, поскольку их нельзя хорошо выполнять в параллельной среде. Например, свойство IDENTITY не поддерживается, как указано в разделе ETL.
Совместимость Transact-SQL с SQL Server SMP реализована еще не полностью, и Microsoft продолжает добавлять функциональные возможности с помощью частых обновлений. Рекомендуется тестировать все существующие сценарии и хранимые процедуры, которые являются частью текущих операций, на предмет работы с новейшими функциональными возможностями, предоставляемыми SQL Server PDW.
Управление и настройка системы▲
SQL Server PDW имеет собственную Центральную консоль администрирования (Central Administration), которая обеспечивает легкое управление и мониторинг системы. Она использует продукт, схожий с SQL Server Management Studio, который имеет представление о многоузловом характере системы и осуществляет мониторинг сессий, запросов, нагрузки, резервного копирования, активность узлов, предупреждений и ошибок.
С точки зрения настройки, лучше начать с простого подхода к SQL Server PDW, начиная с минимальными индексами, как описано в разделе физического проектирования, и тестировать производительность с представительным набором пользовательских запросов, как только данные загружены. Если все работает – прекрасно. Если нет, то можно использовать консоль Central Adminstration для проверки отдельных планов запросов, чтобы узнать, где узкие места. Например, распределение таблицы фактов может быть расфазировано, и большая часть обработки будет приходиться на один узел. В этом случае можно попробовать другой столбец распределения с помощью инструкции CREATE TABLE AS SELECT, как описано выше. Возможно, потребуются индексы для определенных типов запросов. Например, клиенту для запроса могут понадобиться индивидуальные телефонные номера из измерения Customer для каких-то отчетов. Это можно сделать с помощью некластеризованного индекса по телефонным номерам. Такой подход обычно применяется для запросов, которые часто используются и оказывают большое влияние на пользователей.
Дополнительные возможности▲
Parallel Data Warehouse может выполнять несколько дополнительных ролей и функций, помимо обслуживания корпоративного хранилища данных. С позиции информации предприятия, SQL Server PDW может интегрироваться с существующими системами, выступая в качестве системы учета для аналитических данных и предоставляя эти данные ниже на уровень потребителей. С позиции обработки ETL, SQL Server PDW может выступать как крупномасштабный движок ETL, управляющий объемными преобразованиями больших массивов данных. SQL Server PDW может также работать как оперативное хранилище данных, что имеет решающее значение для определенной аналитики.
Интеграция с существующими системами▲
Есть много ситуаций, в которых корпоративные хранилища данных должны передавать большие наборы данных системам ниже по цепочке. Во многих случаях это расширения системы DW/BI в виде витрин данных, которые могут получать информацию от SQL Server PDW с помощью звездообразного соединения. Определение витрины данных достаточно расплывчато, часто оно описывает компонент, который существует по историческим и/или политическим причинам, и добавляет работы, не добавляя большого смысла. Витрины данных и другие нижестоящие потребители данных могут также включать специально построенные архитектурные компоненты. Например, может быть оправдано создание подмножества данных предприятия на отдельном сервере, чтобы обеспечить интеграцию с бизнес-единицами или региональными данными. Мы также встречались с большими блоками данных, экспортируемыми из EDW для поддержки исследований или сбора данных на выделенном сервере. Такие операционные системы, как автоматизация для торговых агентов или системы управления взаимоотношениями с клиентами (CRM), часто импортируют большие подмножества EDW для того, чтобы обеспечить контекст своим процессам. Мы также встречались с тем, как подмножества создаются по конкретным бизнес-причинам. Например, одна компания хотела предоставлять данные о продажах своим клиентам, но, по соображениям безопасности, решила создать отдельную витрину данных для каждого клиента.
Если необходима интеграция с существующими системами, SQL Server PDW поможет в этом. Remote Table Copy (удаленное копирование таблицы) – высокоскоростная функция копирования таблиц, которая может передавать таблицы из SQL Server PDW в SQL Server, работающий на подключенном локально SMP-сервере. Скорость передачи данных может достигать 400 ГБ в час. Как только данные скопированы на целевую машину SQL Server, можно завершить ETL-процесс для должной интеграции его в базу данных с соответствующими индексами, разбиениями и любыми другими необходимыми ограничениями.
Интеграция с существующими системами▲
Если ниже находятся витрины данных, которые были созданы по историческим и/или политическим причинам, и которые больше не отвечают истинным потребностям бизнеса, мы рекомендуем их внимательно изучить. Такой многослойный, мульти-модельный подход приводит к дополнительной значительной работе, тратам времени, избыточности и увеличивает стоимость внедрения системы DW/BI на предприятии. Внедрение системы SQL Server PDW дает возможность изменить архитектуру ранее используемых «довесков», сделать информационную среду предприятия более эффективной и действенной.
Такая стратегия улучшения платформы имеет своей целью заменить существующие системы DW/BI, отключив существующие витрины данных и перенаправив или переписав BI-запросы и отчеты, чтобы они работали непосредственно с данными из SQL Server PDW. Такой подход, как правило, более агрессивен, и требует больше усилий, но, в конечном счете, приводит к созданию более простого, более надежного, более маневренного информационного ресурса предприятия. Простая интеграция SQL Server PDW в существующую среду звучит привлекательно, потому что в краткосрочной перспективе это создает незначительные изменения. Тем не менее, в долгосрочной перспективе Вы рискуете увековечить неэффективные, запутанные и дорогостоящие системы.
Возможность усовершенствования SQL Server PDW как механизм преобразования▲
Организациям, работающим с особо крупными наборами данных и сталкивающимся с ограничениями по нагрузкам, может не подойти отдельная ETL-система, обрабатывающая данные до их загрузки в SQL Server PDW. В этих случаях SQL Server PDW может работать как крупномасштабный механизм преобразования в рамках общей архитектуры EDW. Такой подход обычно включает в себя загрузку данных непосредственно в таблицы базы данных SQL Server PDW, а затем выполнение ETL-преобразования, по мере того как операции INSERT-SELECT присоединяют промежуточные таблицы к таблицам измерений для массового преобразования суррогатных ключей. Такой подход позволяет применять на полную мощность параллельное окружение в ядре ETL-процессов.
Возможности реального времени▲
Хотя большинство аналитических данных в хранилище данных не нужно загружать на основе «менее чем 24 часа», для реализации некоторых бизнес-возможностей необходима более частая загрузка данных. Параллельный процесс загрузки SQL Server PDW поддерживает «оперативную загрузку» на изолированном уровне Read Uncommitted (неподтвержденное чтение, Dirty Reads). Загрузка может осуществляться тогда, когда пользователи осуществляют запросы к таблицам, и такие загрузки оказывают низкое влияние на общую производительность одновременно выполняющихся запросов.
Заключение▲
SQL Server Parallel Data Warehouse – жизнеспособная платформа для поддержки крупномасштабных хранилищ данных в сотни терабайт. Характер системы позволяет относительно легко конфигурировать, устанавливать, настраивать, управлять и расширять ее. SQL Server PDW позволяет осуществлять параллельную обработку запросов к многомерным моделям атомарных данных для достижения целей подхода Кимбалла в части производительности, удобства и гибкости запросов с использованием информационных ресурсов предприятия.