Oracle Exadata
Одним из последних инновационных решений компании Oracle стало создание Oracle Exadata – нового аппаратно-программного продукта, призванного решить проблему эффективной организации хранения данных. Среди основных преимуществ Oracle Exadata стоит отметить десятикратное ускорение запросов, увеличение места для хранения данных и возможность линейного роста производительности при добавлении новых ячеек.
Рассмотрим аппаратную архитектуру Oracle Exadata. Применение Exadata Storage Server совместно с Sun Oracle Database Machine позволило разработчикам создать хранилище, оптимизированное для Oracle Database и обеспечить высокую производительность.
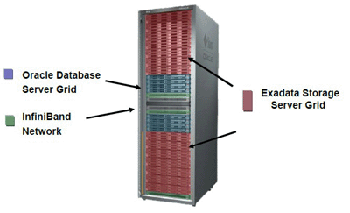
Рисунок 1.
Внешний вид Sun Oracle Database Machine показан на рисунке 1, а внешний вид Sun Exadata Storage Server Hardware и Х4170 Database Server Hardware с обозначением комплектующих и их характеристик приведены на рисунках 2 и 3 соответственно.
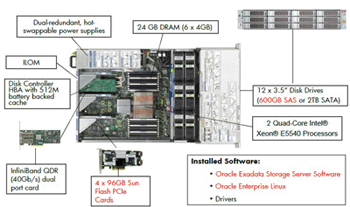
Рисунок 2.
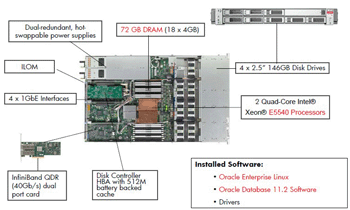
Рисунок 3.
Новая технология рационального заполнения пространства, реализованная в Oracle Exadata, позволяет устанавливать до 8 стоек и масштабировать в них сотни серверов хранения, а применение технологии FlаshFirе в Exadata позволяет увеличить пропускную способность до 50 Гб/сек, а запросы выполнять со скоростью 500 Гб/сек.
Теперь рассмотрим программную архитектуру Oracle Exadata (рисунок 4)
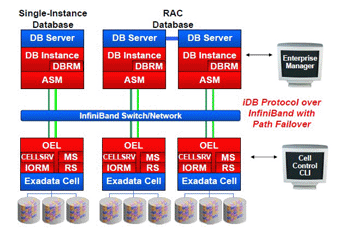
Рисунок 4.
Ячейки Exadata реализуют механизм передачи запросов на сторону хранилища (scan offload) с тем, чтобы значительно уменьшить объем данных возвращаемых на сторону серверов БД, выполняя следующие действия:
- фильтрация строк на основе "where" предиката
- фильтрация колонок
- фильтрация соединений (join)
- фильтрация инкрементального backup
- фильтрация зашифрованных данных
- работа с функциями Data Mining.
Рассмотрим преимущества технологии Smart Scan схематически на конкретном примере. Итак, предположим, мы – администраторы телекоммуникационной компании, и нам необходимо отправить в БД запрос с целью идентифицировать заказчиков, которые тратят более 200$ за один звонок. Информация о таких заказчиках занимает 2 МБ в таблице размером 1 ТБ, при этом вся логика лежит на стороне БД. Очень большой процент данных будет отброшен при обработке на стороне сервера БД и тем самым повлияет на производительность так, как отбрасывание данных будет потреблять ресурсы. Схематически этот процесс показан на рисунке 5.
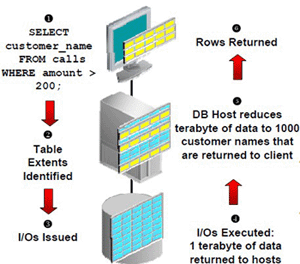
Рисунок 5.
Теперь эту же задачу решим в режиме Smart Scan (рисунок 6). Для решения задачи серверу БД будут возвращаться только колонки «customer_name» и записи «where amount > 200», соответственно никакой сортировки и отброса данных выполняться не будет так, как вся фильтрация данных будет осуществляться на стороне Exadata сервисов, что существенно повысит продуктивность.
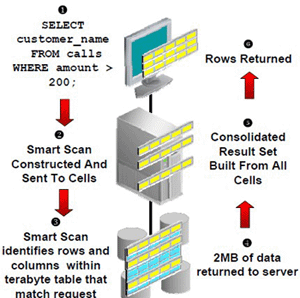
Рисунок 6.
Работа в режиме Smart Scan не требует изменения приложения или SQL кода и в случае выхода из строя ячейки во время smart scan незавершенная часть запроса прозрачно перенаправляется на ячейку, содержащую копию данных.
Технология гибридного колоночного сжатия позволяет сжать данные для хранения в 10 раз, а редко используемые данные – даже в 50 раз, что существенно повышает эффективность использования пространства БД. Эта технология реализуется следующим образом: логический блок сжатия, образуемый 4 блоками по 8 кбит каждый, организует данные по колонкам во время загрузки, сжимая каждую колонку отдельно (рисунок 7).

Рисунок 7.
Также новинкой в Oracle версии 11g Release 2 стало применение Exadata индексов на стороне хранилища, которые поддерживают знания о распределении данных в таблицах в памяти и исключают ввод-вывод для тех дисков, где значения «мин» и «макс» не соответствуют условию «where», при чем делают это полностью автоматически и прозрачно.
В версии 11g R2 реализован механизм параллельного выполнения операций в памяти. Чтобы лучше понять, как он работает, мы рассмотрим его работу на рисунке 8. Итак, мы делаем SQL запрос, система определяет размер таблицы и если:
- таблица очень маленькая, то читаем ее в кэш на любом узле;
- таблица очень большая, то выполняем прямое чтение с диска;
- таблица имеет размер, оптимальный для параллельного выполнения в памяти, то фрагменты таблицы читаются в кэш разными узлами, и только параллельные сервера на том же узле получают доступ в фрагментам объекта.
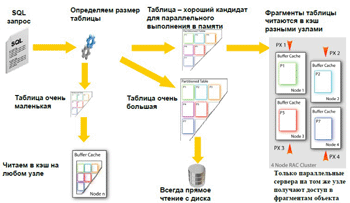
Рисунок 8.
Также стоит упомянуть о DBFS – масштабируемой разделяемой файловой системе, которая позволяет хранить ETL staging, скрипты и отчеты, как SecureFile LOBs в таблицах БД в Exadata, и позволяет в БД используя External Tables с производительностью от 5 до 7 Гб/сек, что более производительно, чем использовать High-End NAS Filer.
В заключение хочу отметить, что в Oracle Exadata:
- в архитектуре Exadata Storage нет точек сбоя;
- технология Hardware Assisted Resilient Data (HARD) встроена в Exadata Storage, предотвращает повреждение данных в результате сбоя или ошибки;
- Data Guard обеспечивает защиту данных, в том числе географически распределенную, также защиту данных от повреждения;
- резервное копирование осуществляется с помощью RMAN;
- обеспечивается совместимость Exadata и традиционных хранилищ;
- различных типов нагрузки могут быть объединены в одной системе.
Все это дополнительно подтверждает эффективность Oracle Exadata, реализованной в Oracle версии 11g Release 2.
http://www.oracloid.ru