Реализация ETL-процессов корпоративного хранилища данных
ETL-процесс (Extract Transform Load) представляет собой реализацию в специализированном программном средстве логики преобразования по заданным правилам к заданной структуре и качеству извлеченных из систем-источников данных и их дальнейшую загрузку в область постоянного хранения корпоративного хранилища.
Для реализации ETL-процессов существует ряд программных средствах, таких как IBM DataStage, Informatica Data Power, Oracle Werehouse Builder, Talend Open Studio и другие. ETL-процесс можно реализовать и путем самостоятельного написания скриптов и программ. Но при наличии свободно распространяемых ETL-решений этот путь выглядит по меньшей мере странно.
ETL-процессы корпоративного хранилища данных, с точки зрения наполняемых ими сущностей, можно условно разделить на следующие пять типов:
- процессы загрузки справочников и классификаторов (НСИ);
- процессы загрузки сущностей, описывающих связи;
- процессы загрузки фактических значений;
- процессы агрегации и подготовки витрин данных;
- процессы подготовки данных для внешних систем.
Целью данной статьи является описание логики работы / реализации ETL-процессов загрузки справочников и классификаторов и ETL-процессов загрузки фактических данных.
На рисунке ниже в формате DFD-диаграммы (Data Flow Diagram) изображены основные процессы формирования данных справочников и классификаторов, объекты области временного хранения (Staging Area), потоки данных между процессами и объектами хранения (пунктирной линией отображается поток управления).
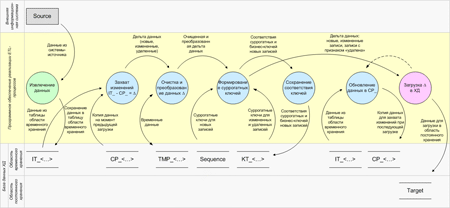
В первую очередь осуществляется полное извлечение данных справочника из внешней системы-источника (таблица базы данных, структурированный файл, web-сервис и т.п.) и сохранение этих данных в интерфейсную таблицу области временного хранения базы данных хранилища. Далее производится захват изменений, произошедших с данными в источнике с момента последней загрузки в хранилище: данные из «IT_...» таблицы сравниваются с данными из таблицы «CP_...» - данными на момент предыдущей загрузки; по результатам сравнения формируется дельта записей, для каждой из которых проставляется признак типа произошедшего с ней изменения (запись добавлена (новая), запись изменилась, удалена в источнике).
После захвата изменений осуществляется очистка и трансформация полученных записей (приведение значений к единому формату, требуемой структуре, например, к структуре медленно меняющихся измерений, осуществление замены бизнес-ключей других справочников на суррогатные и т.д.). При этом для сохранения промежуточных результатов могут использоваться таблицы «TMP_...» базы данных.
После проведения преобразований для новых записей из последовательности базы данных (Sequence) формируются суррогатные ключи, а для измененных записей суррогатные ключи определяются на основе сохраненного в таблице «KT_...» их соответствия бизнес-ключам. Соответствия ключей новых записей сохраняются в таблицу «KT_...».
Полученный набор новых, измененных и «удаленных» записей загружается в соответствующую (целевую) таблицу области постоянного хранения. Новые записи добавляются (insert), измененные модифицируются (update), для удаленных проставляется признак удаления (если он предусмотрен в таблице).
По окончанию успешной загрузки данных в область постоянного хранения производится копирование записей из таблицу «IT_...» в таблицу «CP_...» для осуществления захвата изменений при дальнейшей загрузке.
Ниже представлена DFD-диаграммы процесса загрузки в хранилище данных фактических значений.
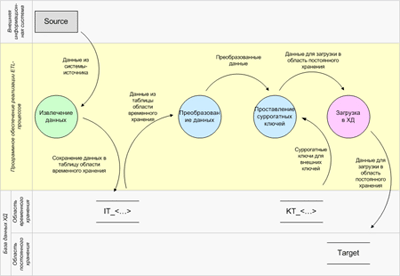
Как и в случае с процессом загрузки справочников и классификаторов, в первую очередь выполняется извлечение фактических данных (финансовые проводки, телефонные звонки, платежи и т.п.) из системы-источника и сохранение их в таблице «IT_...» области временного хранения. Но в отличие от процессов формирования НСИ, фактические данные извлекаются только за нужный период (как правило, в таблицах существует поле с нужной датой). Далее осуществляется преобразование данных: смета типов, приведение к нужной структуре, обогащение и т.п. После чего производится замена бизнес-ключей на суррогатные на основании соответствий, хранящихся в таблицах «KT_...». Конечным шагом является загрузка (Insert) фактических данных в таблицу области постоянного хранения.
Префиксы таблиц области временного хранения «IT_...», «CP_...», «TMP_...», «KT_...» вводятся для удобства их дальнейшего сопровождения и работы с ними.